
AI: Going up from 100,000 AI GPU data centers. RTZ #551


I’ve talked about the AI Compute race ‘Table Stakes’ ante for the big tech companies being at a 100,000 mostly Nvidia GPUs in a super-sized AI data center, with attendant Power moving to the Gigawatts. Meta, xAI, Microsoft/OpenAI and others are actively in this race with Nvidia AI Infrastructure, and the numbers are going up by 2x or more. Mostly to Nvidia’s benefit for now.
The WSJ explains in “AI’s Future and Nvidia’s Fortunes Ride on the Race to Pack More Chips Into One Place”:
”Musk’s xAI and Meta are among firms building clusters of advanced chips”.
“Tech titans have a new way to measure who is winning in the race for AI supremacy: who can put the most Nvidia chips in one place.”

“Companies that run big data centers have been vying for the past two years to buy up the artificial-intelligence processors that are Nvidia’s specialty. Now some of the most ambitious players are escalating those efforts by building so-called super clusters of computer servers that cost billions of dollars and contain unprecedented numbers of Nvidia’s most advanced chips.”
The two companies ahead in the 100,000 GPU supercluster data center race are meta and xAI:
“Elon Musk’s xAI built a supercomputer it calls Colossus—with 100,000 of Nvidia’s Hopper AI chips—in Memphis in a matter of months. Meta Chief Executive Mark Zuckerberg said last month that his company was already training its most advanced AI models with a conglomeration of chips he called “bigger than anything I’ve seen reported for what others are doing.”
And the table stakes for base chips are up and to the right:

“A year ago, clusters of tens of thousands of chips were seen as very large. OpenAI used around 10,000 of Nvidia’s chips to train the version of ChatGPT it launched in late 2022, UBS analysts estimate.”
“Such a push toward larger super clusters could help Nvidia sustain a growth trajectory that has seen it rise from about $7 billion of quarterly revenue two years ago to more than $35 billion today. That jump has helped make it the world’s most-valuable publicly listed company, with a market capitalization of more than $3.5 trillion.”
But as I’ve discussed before, installing more chips is not a straight line, straightforward task:

“Installing many chips in one place, linked together by superfast networking cables, has so far produced larger AI models at faster rates. But there are questions about whether ever-bigger super clusters will continue to translate into smarter chatbots and more convincing image-generation tools.”
“The continuation of the AI boom for Nvidia also depends in great measure on how the largest clusters of chips pan out. The trend promises not only a wave of buying for its chips but also fosters demand for Nvidia’s networking equipment, which is fast becoming a significant business and brings in billions of dollars of sales each year.”

And the Wall Street ‘Guidance’ for now is up and to the right:
“Nvidia Chief Executive Jensen Huang said in a call with analysts following its earnings Wednesday that there was still plenty of room for so-called AI foundation models to improve with larger-scale computing setups. He predicted continued investment as the company transitions to its next-generation AI chips, called Blackwell, which are several times as powerful as its current chips.”
“Huang said that while the biggest clusters for training for giant AI models now top out at around 100,000 of Nvidia’s current chips, “the next generation starts at around 100,000 Blackwells. And so that gives you a sense of where the industry is moving.”
The boasting has begun:
“The stakes are high for companies such as xAI and Meta, which are racing against each other for computing-power bragging rights but are also gambling that having more of Nvidia’s chips, called GPUs, will translate into commensurately better AI models.”
And industry analysts are jumping in on the AI Scaling debate, that I’ve discussed in two parts:

“There is no evidence that this will scale to a million chips and a $100 billion system, but there is the observation that they have scaled extremely well all the way from just dozens of chips to 100,000,” said Dylan Patel, the chief analyst at SemiAnalysis, a research firm.”
“In addition to xAI and Meta, OpenAI and Microsoft have been working to build up significant new computing facilities for AI. Google is building massive data centers to house chips that drive its AI strategy.”
And for now Jensen is cheering his top customers on:
“Huang marveled on a podcast last month at the speed with which Musk had built his Colossus cluster and affirmed that more, larger ones were on the way. He pointed to efforts to train models distributed across multiple data centers.”
“Do we think that we need millions of GPUs? No doubt,” Huang said. “That is a certainty now. And the question is how do we architect it from a data center perspective.”

“Construction on a Microsoft data center in Mount Pleasant, Wis., earlier this year.”
The biggest customers are also talking up their plans:
“Unprecedented super clusters are already getting airplay. Musk posted last month on his social-media platform X that his 100,000-chip Colossus super cluster was “soon to become” a 200,000-chip cluster in a single building. He also posted in June that the next step would probably be a 300,000-chip cluster of Nvidia’s newest chips next summer.”
“The rise of super clusters comes as their operators prepare for the Blackwell chips, which are set to start shipping out in the next couple of months. They are estimated to cost around $30,000 each, meaning a cluster of 100,000 would cost $3 billion, not counting the price of the power-generation infrastructure and IT equipment around the chips.”
“Those dollar figures make building up super clusters with ever more chips something of a gamble, industry insiders say, given that it isn’t clear that they will improve AI models to a degree that justifies their cost.”
The near term goals are better AI Reasoning and Agents, as I’ve discussed at length:
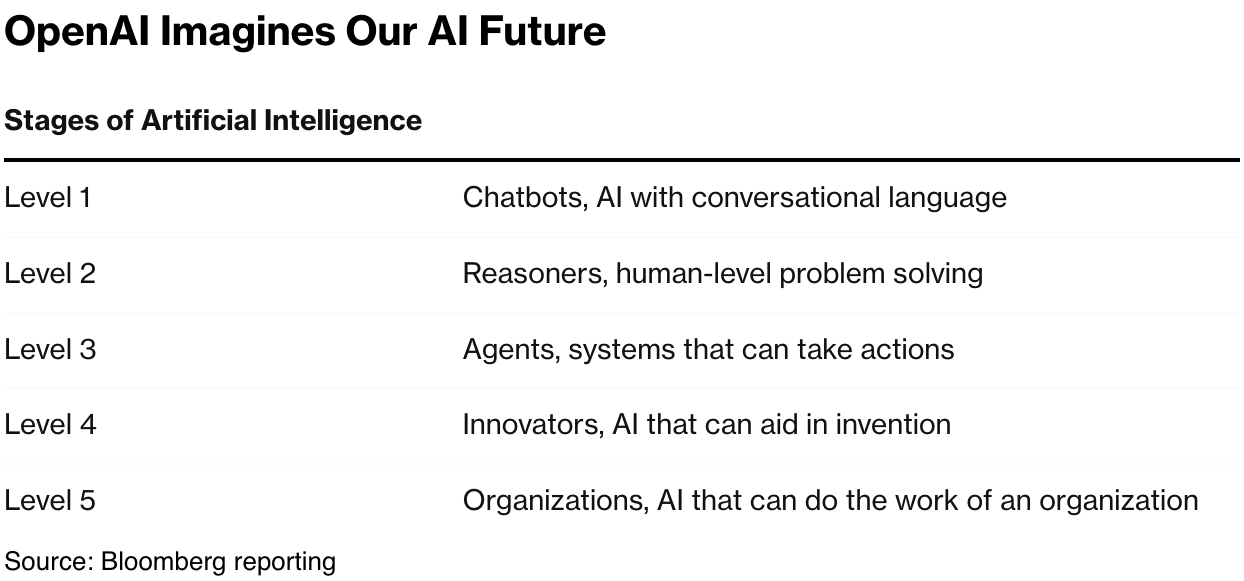
As the AI data centers become bigger with GPU chips and infrastructure, so does the challenge of keeping the hardware working at scale:
“New engineering challenges also often arise with larger clusters. Meta researchers said in a July paper that a cluster of more than 16,000 of Nvidia’s GPUs suffered from unexpected failures of chips and other components routinely as the company trained an advanced version of its Llama model over 54 days.”
Cooling being a critical necessity, especially with the new Nvidia Blackwell GPUs:
“Keeping Nvidia’s chips cool is a major challenge as clusters of power-hungry chips become packed more closely together, industry executives say, part of the reason there is a shift toward liquid cooling where refrigerant is piped directly to chips to keep them from overheating.”

“And the sheer size of the super clusters requires a stepped-up level of management of those chips when they fail. Mark Adams, chief executive of Penguin Solutions, a company that helps set up and operate computing infrastructure, said elevated complexity in running large clusters of chips inevitably throws up problems.”
“When you look at everything that can go wrong, you could be utilizing half of what your capital expenditure was because of all these things that can break down,” he said.”
AI data centers are growing larger in multiples this AI Tech Wave. Something to watch scale up at least into 2026 and likely beyond to AGI. However defined. Stay tuned.
(NOTE: The discussions here are for information purposes only, and not meant as investment advice at any time. Thanks for joining us here)



