
AI: Nvidia's challenging transition to Blackwell AI GPU Infrastructure. RTZ #543


Most Tech Waves look inevitable in their Moore’s Law style Scaling in hindsight. Both in terms of the hardware and software layers in the tech stacks below. Our memories smooth out the difficult transitions sometimes from one generation to the next. Over upgrade cycles that sometimes run into decades. Whether it was the transition from Microsoft DOS to WIndows 95 over 15 plus years, to Intel x86 to Pentium chips and beyond over years as well.
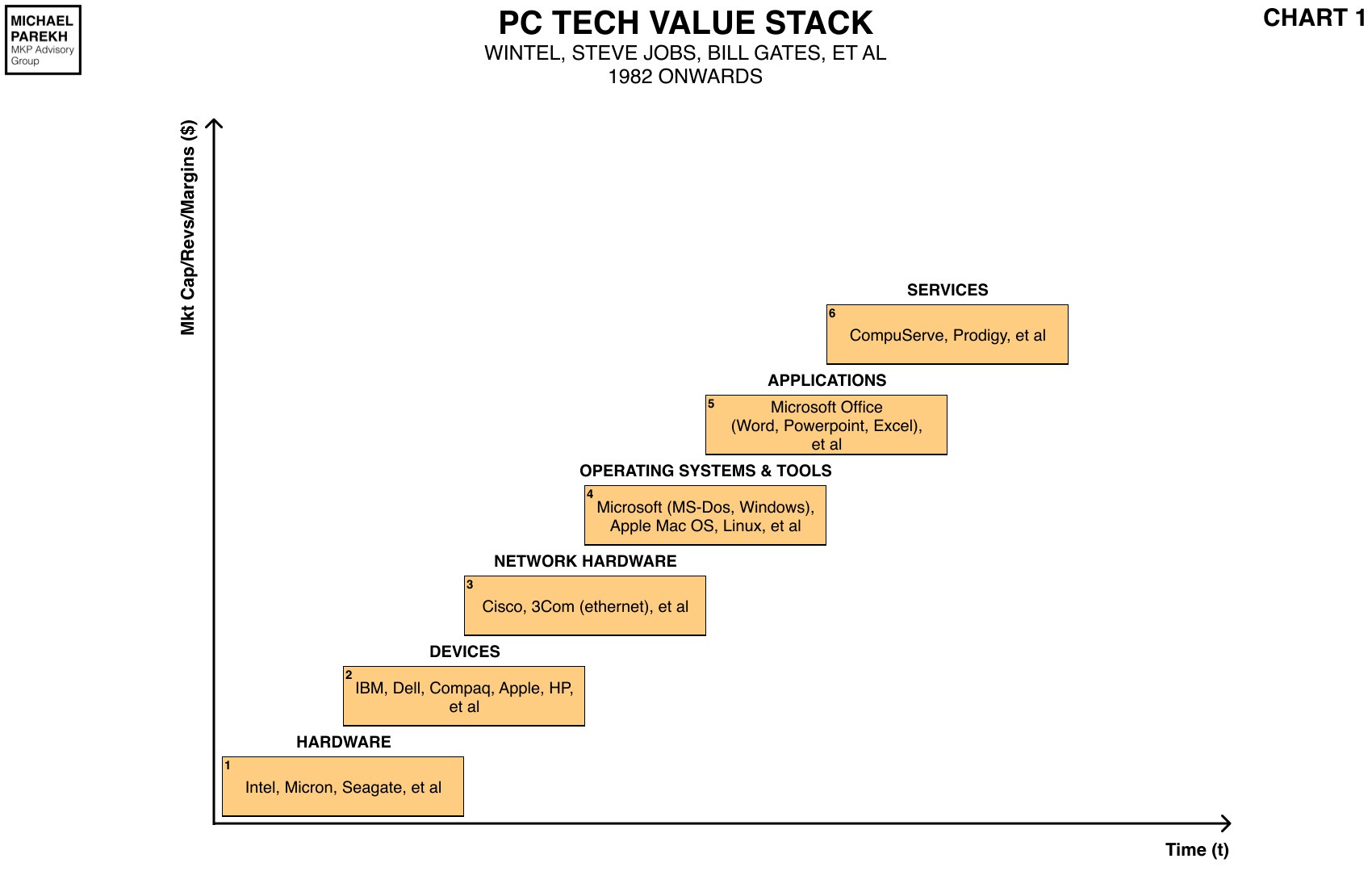
It applies as well to the Internet access transition from a narrow-band dial-up internet from AOL in the nineties, to the wireline broadband of the 2000s, to the wireless broadband of the 2010s. We think these were smooth transitions, that went from one to the next ever couple of years like clockwork. But they did not. There were gnarly tech, financial, regulatory and so many other issues to be worked out, both within and across tech companies. And across various levels of the Tech Stacks.

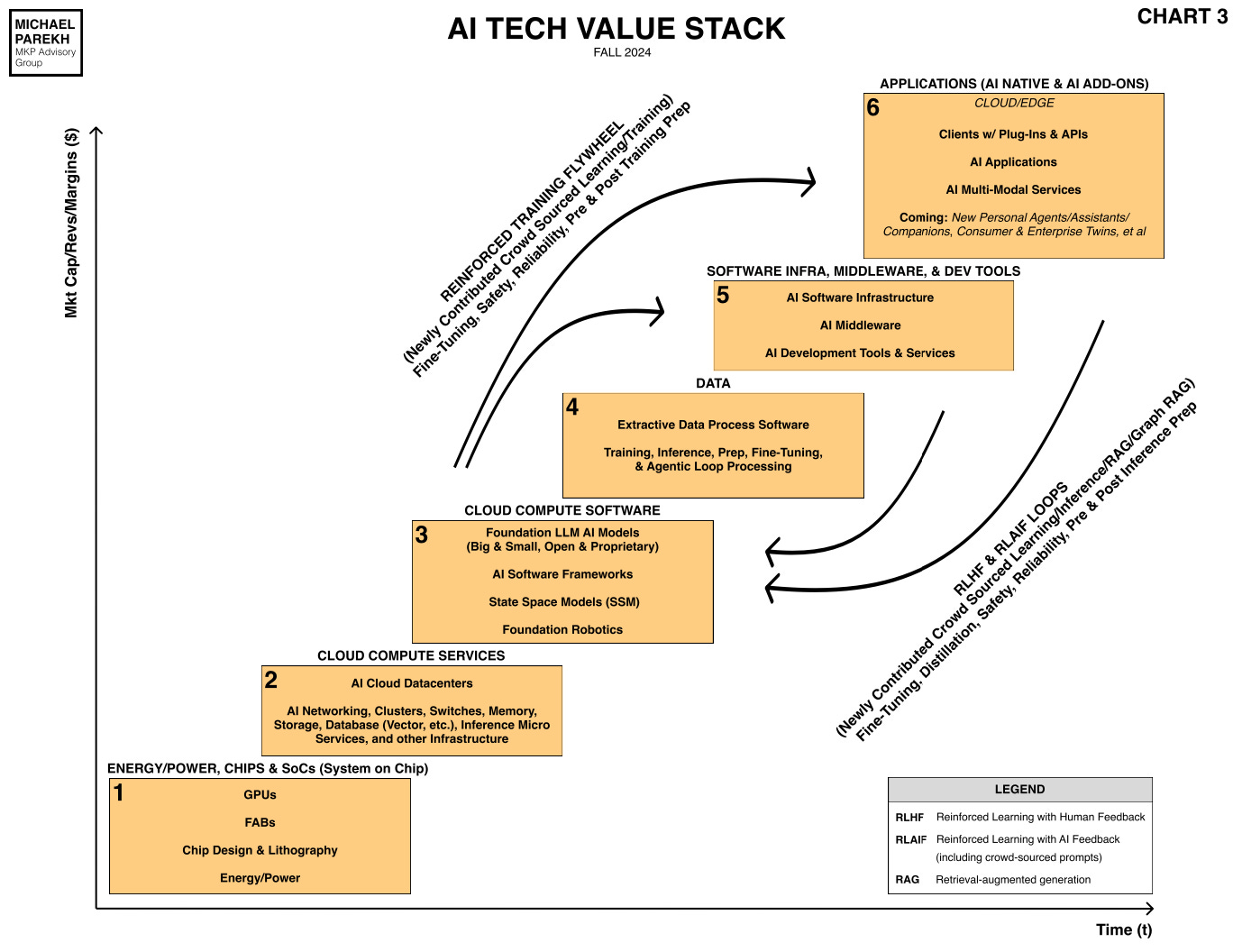
A similar thing is going on right now on the second anniversary of the OpenAI’s ChatGPT moment. Whether its the delays in Scaling of the software behind Large AI models themselves that I’ve written about, to the scaling of the AI GPUs from Nvidia. From its Hopper architecture to the upcoming Blackwell chips and their delays, to likely Rubin chips that come in a couple of years and beyond.
The Information outlines the current bumpy Blackwell transition in “Nvidia Customers Worry About Snag With New AI Chip Servers”:
“Nvidia is grappling with new problems related to its much-anticipated Blackwell graphics processing units for artificial intelligence: how to prevent them from overheating when connected together in the customized server racks it has designed.”

“In recent months, Nvidia has asked its suppliers to change the design of the racks several times as it has tried to overcome the overheating problems, according to Nvidia employees who have been working on the issue, as well as several customers and suppliers with knowledge of it. Word of the repeated design changes has sparked anxiety among customers about a potential delay in when they will be able to use the racks.”
Upgrading AI Data Centers is now a multi-trillion dollar plus set of investments, and the technical roadmaps are complex to build these for all the parties involved. Each different from one build to another.

“Nvidia already had to delay the production and delivery of the Blackwell GPUs by at least a quarter after running into design flaws in the chips. Both episodes highlight the difficulties in its quest to meet high customer demand for its AI hardware.”
“What makes the new server racks significant is that they combine 72 of Nvidia’s AI chips, an extraordinarily high number. AI developers are hoping that would allow them to train larger AI models much faster.”
“Major customers including Microsoft, Meta Platforms and Elon Musk’s xAI enthusiastically greeted Nvidia’s announcement in March about producing a 72-chip rack.”
Each of Nvidia’s top customers have their own priorities in designing and standing up their multi-billion dollar data centers. For a wide range of AI applications from training to inference, from synthetic data/content creation and then their use again in reinforcement learning loops of the underlying models over and over again.

“Now, though, some big customers are concerned. While Nvidia often changes its server designs before launch, changes to the Blackwell racks have come late in the production process, according to several customers and suppliers. However, Nvidia may still be able to deliver the racks to customers by the end of the first half next year, in line with its original schedule, and it hasn’t notified customers of a delay.”
“Two executives at large cloud providers that have ordered the new chips said they are concerned that such last-minute difficulties might push back the timeline for when they can get their GPU clusters up and running next year.”
Part of the issue is that a lot of the software layers that act as the ‘AI Reasoning and Agentic’ glue for the hardware and software is currently just moving from the research labs to commercialization at scale. These are the new ‘AI Table Stakes’ as discussed before.
“The executives say they need at least several weeks to test the system and iron out possible kinks, especially given the novel design and unprecedented complexity. Some customers, such as Microsoft, plan to customize their Blackwell racks by replacing some components to suit their data centers, but the final design is still dependent on elements Nvidia needs to finalize, according to someone who has been working on the design.”
“A spokesperson for Nvidia declined to comment on whether the company has finalized the Blackwell rack designs. Nvidia’s “GB200 systems are the most advanced computers ever created” and “integrating them into a diverse range of data center environments requires co-engineering with our customers,” the spokesperson said. “The engineering iterations are normal and expected.”
“Customers are under significant pressure to launch data center server clusters before their competitors do, so their anxieties probably aren’t surprising to Nvidia CEO Jensen Huang.”
Nvidia is in the midst of it all of course building and productizing its core AI Tech Infrastructure for Data Centers to come, and widening its AI CUDA software moat.
“Delivery of our components and our technology and our infrastructure and software is really emotional for people, because it directly affects their revenues, it directly affects their competitiveness,” Huang said during the Goldman Sachs technology conference in San Francisco in September. “And so we probably have more emotional customers today…and deservedly so.”
“The situation also reflects the tremendous dependency some of its largest customers have on Nvidia, even as they develop competing AI chips.”
“Huang unveiled the racks at the same time as the Blackwell series of chips, at the company’s annual GTC customer conference in March. Nvidia already makes networking cables to connect its chips, and Huang’s pitch was that customers could ensure a faster connection by ordering the racks in addition to the chips and the cables.”
Collectively, these systems Scale the hardware to very meaningful levels.

“Fully loaded, the 72-GPU rack weighs 3,000 pounds (1.5 tons) and is taller than an average household refrigerator. Nvidia promoted it as the best way to connect the chips together for the fastest performance.”
“Still, the rack and its dense positioning of dozens of GPUs was the most complicated design Nvidia had ever come up with, according to three people who work on it or have seen it. A few months after publicly unveiling the racks, Nvidia engineers testing the new system found that the racks did not work properly. Connecting too many of the highly sophisticated chips together caused them to overheat, making the servers in the racks less reliable and hurting their performance, according to two people involved in the server production.”
Cooling these systems is one of the biggest challenges, as I’ve discussed separately.

“The racks also require water cooling, as opposed to conventional air cooling, because the chips need more power and the servers get hotter than they did with previous generations of GPUs. Most AI developers and data center providers have never cooled large arrays of servers using water. That’s another reason customers have been anxious about the design.”
“Nvidia also has run into problems with a smaller, 36-chip rack that got too hot, according to two Nvidia employees with direct knowledge of the matter. It isn’t clear whether the company has resolved the problem.”
And the transition between Hopper to Blackwell may need some zigs back before they zag again:
“Hopping Back to Hopper”

“In the meantime, customers are considering alternatives. One executive at a cloud firm that had ordered the racks said the Blackwell issues are causing the company to consider instead buying more of Nvidia’s current-generation Hopper chips, also known as H100s or H200s.”
“Customers that decide to buy more Hopper chips instead of waiting for Blackwells could boost Nvidia’s short-term earnings because analysts and investors estimate the Hopper series generates higher margins. But it may not bode well for Nvidia’s future revenue growth, as customers who have switched to Hoppers may not order as many Blackwell chips and NVLink servers.”
These bumps in the road are to be expected in tech waves, and this AI Tech Wave is no exception. Both for the LLM AI software, and the AI GPU chips, the data centers, and their Power requirements, in the six Boxes above. There are inevitable twists and turns in the road ahead. Stay tuned.
(NOTE: The discussions here are for information purposes only, and not meant as investment advice at any time. Thanks for joining us here)

