
AI: Perfecting 'Synthetic Data'. RTZ #461


From the beginning to the end, LLM AI models of every size and shape are as fragile as a Souffle. It’s due to their reliance at every stage, from training to inference, and the reinforcement learnings curves in the middle, on the DATA that feeds the models.
The tens of billions of dollars being invested by most of the big tech companies in this AI Tech Wave is focused on the holy grail of Scaling AI to bigger and better Foundation LLM AI models. By feeding them ever larger amounts of data.

So that quest in turn hinges on finding ever more sources of Data bigger than what exists on the global public internet to date. And that in turn currently hinges on a race to create ‘Synthetic Data’ from real world data. And the current early technologies here are as resilient as a souffle.
Earlier this summer, in “Debate continues over AI ‘Synthetic Data”, I highlighted the the efforts and debate underway on both sides of the issue:
“The cons include, ‘model collapse’, pros point to net Data nirvana when done right”.
This debate gets some more updates in the NY Times’ “When AI’s Output is a Threat to AI Itself”:
“As A.I.-generated data becomes harder to detect, it’s increasingly likely to be ingested by future A.I., leading to worse results.”
“The internet is becoming awash in words and images generated by artificial intelligence.”
“Sam Altman, OpenAI’s chief executive, wrote in February that the company generated about 100 billion words per day — a million novels’ worth of text, every day, an unknown share of which finds its way onto the internet.”
The piece however changes the context of Sam Altman’s X/tweet by skipping the second part. Here’s the full tweet for fuller context:
“Openai now generates about 100 billion words per day.”
“All people on earth generate about 100 trillion words per day.”

This context if important to understand how EARLY we are in AI generating new data as a rivulet feeding into the oceans of real data that humans create daily.
I point this out because the NY Times makes some valid points on both sides of the Synthetic Data debate on both sides. But it’s important to note that we’re in the earliest days of this Data collection, refinement, and subsequent Synthetic Data creation.

The piece does go onto to provide some additional points and VIVID examples on both sides of the debate. And is worth reading in full. In particular, I’d highlight this segment with some examples under this provocative sub-headline “Degenerative AI”. They outline problems with synthetic data generated in both text and image reiteration around synthetic data, and highlighted the core ‘model collapse’ problem around both simplified approaches:

“This problem isn’t just confined to text. Another team of researchers at Rice University studied what would happen when the kinds of A.I. that generate images are repeatedly trained on their own output — a problem that could already be occurring as A.I.-generated images flood the web.”
“They found that glitches and image artifacts started to build up in the A.I.’s output, eventually producing distorted images with wrinkled patterns and mangled fingers.”
But then, they go on to describe the solution that AI researchers are currently very focused on solving these ‘model collapse’ problems:
“The researchers found that the only way to stave off this problem was to ensure that the A.I. was also trained on a sufficient supply of new, real data.”
That solution has its own set of challenges, but far from an insurmountable one in these early days, as they continue to underline:
“This doesn’t mean generative A.I. will grind to a halt anytime soon.”
“The companies that make these tools are aware of these problems, and they will notice if their A.I. systems start to deteriorate in quality.”
So the debate over the nascent stage of ‘Synthetic Data’ to feed the voracious appetites of next generatio LLM AI models continue. It’s important to continually track the issues and the progress against them.
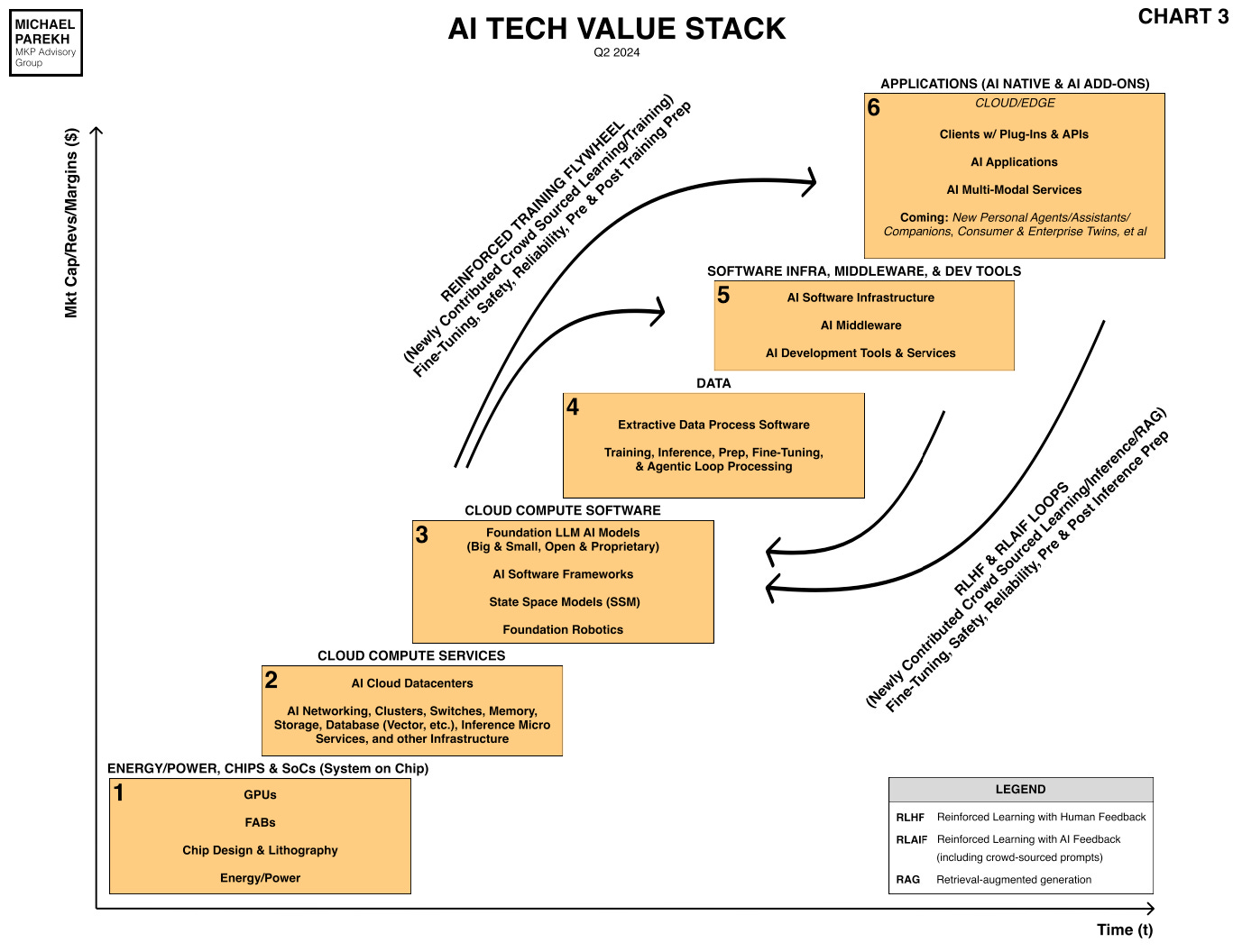
Especially given the challenges and opportunities of the next several iterations of AI Scaling, up and down the AI Tech Stack above. It is ALL about how we Scale Box no. 4, ‘Data’, in particular, to keep the AI reinforcement learning loops going at full tilt.
In the end, we hopefully get an exquisite Souffle, every time. Stay tuned.
(NOTE: The discussions here are for information purposes only, and not meant as investment advice at any time. Thanks for joining us here)



