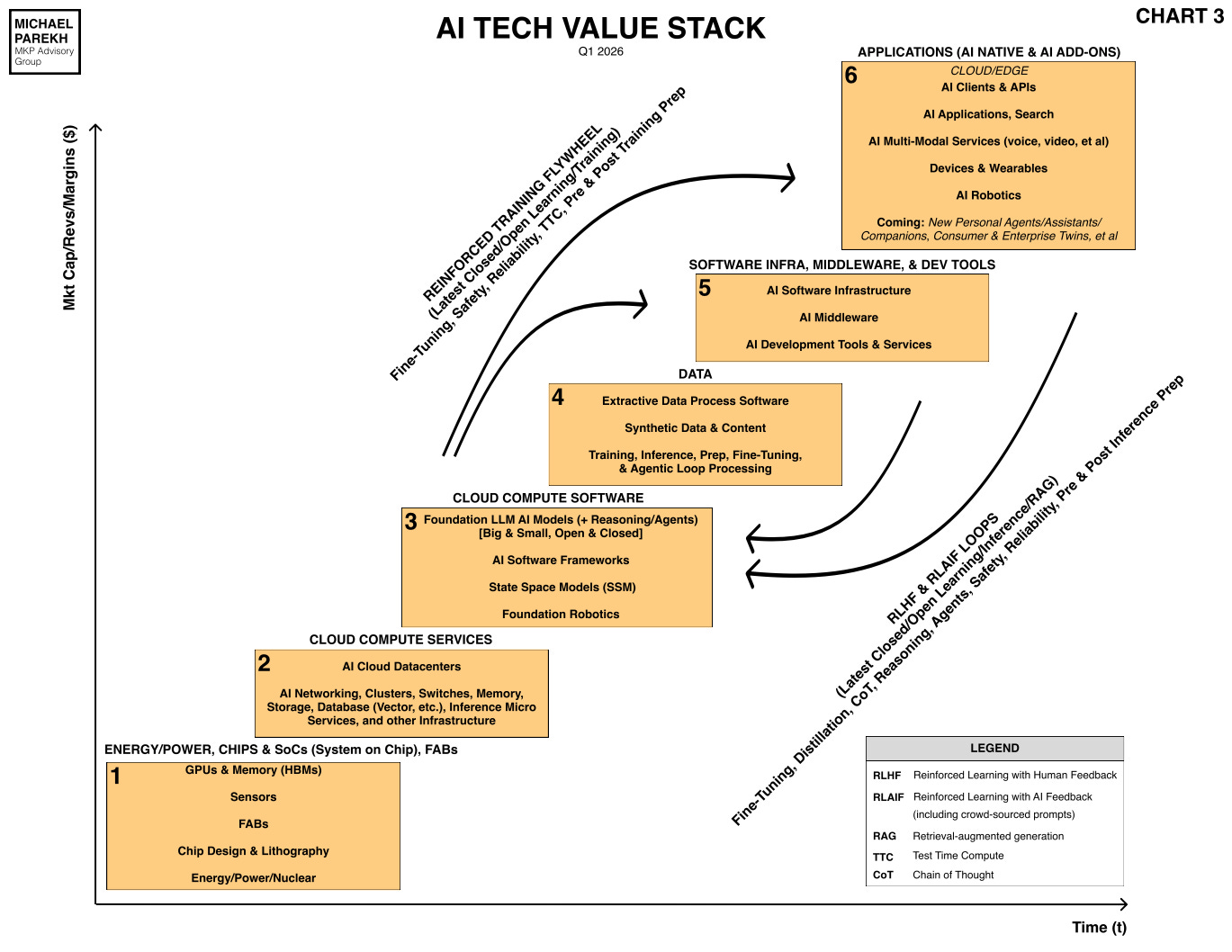
When the history books are written about this AI Tech Wave, however it turns out, two issues will be closely examined for their progress vs their initial ‘AI show-stopping’ nature,
The first as mentioned above, is AI Hallucinations. Long understood to be an ongoing nature of AI computing done through probability matrix math rather than deterministic computing done by retrieving vetted information from data bases to provide answers to users when asked. The latter is how we’ve done computing for decades. The former is how we are rebuilding all computing up and down the AI Tech Stack below, at costs of trillions.
AI Hallucinations is when the AI systems provide answers that are not in a ‘system of record’, vetted database. They’re probabilistic guesses and they are wrong.
Even the best AI systems today from OpenAI, Anthropic on the closed side and all the ones on the open side, hallucinate every day and every use. And provide the ‘wrong answer at least 20% or more of the time. There are no easy solutions other than using traditional computing systems based on deterministic computing to work with the AI systems to create hybrid approaches.
Again, I’ve long described AI Hallucinations as a ‘Forever Problem’. And there’s not much on the horizon other than the hybrid approaches above that can provide 100% solutions by the end of the decade. Maybe beyond that with new AI Research approaches.
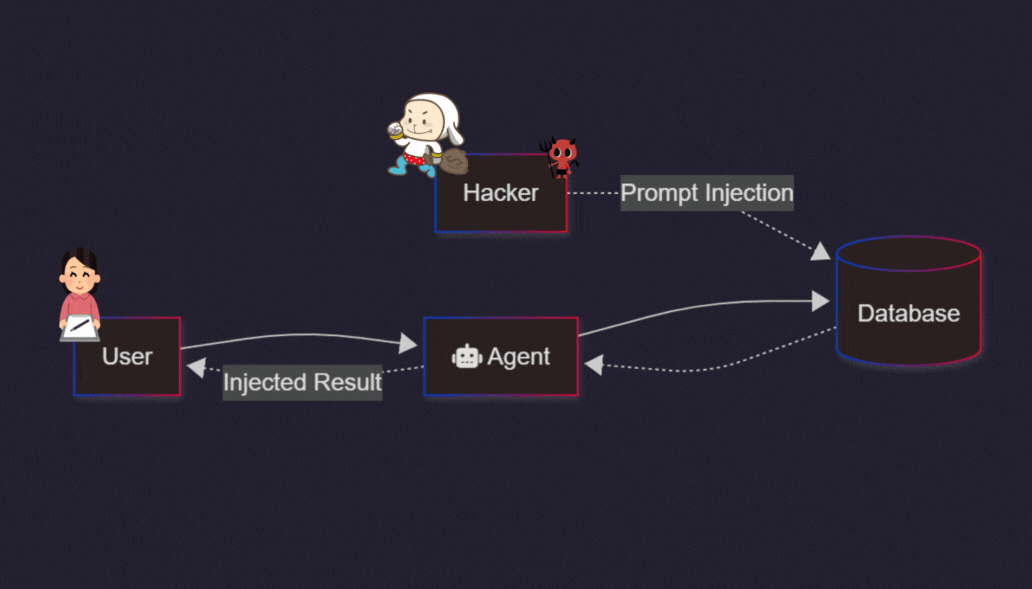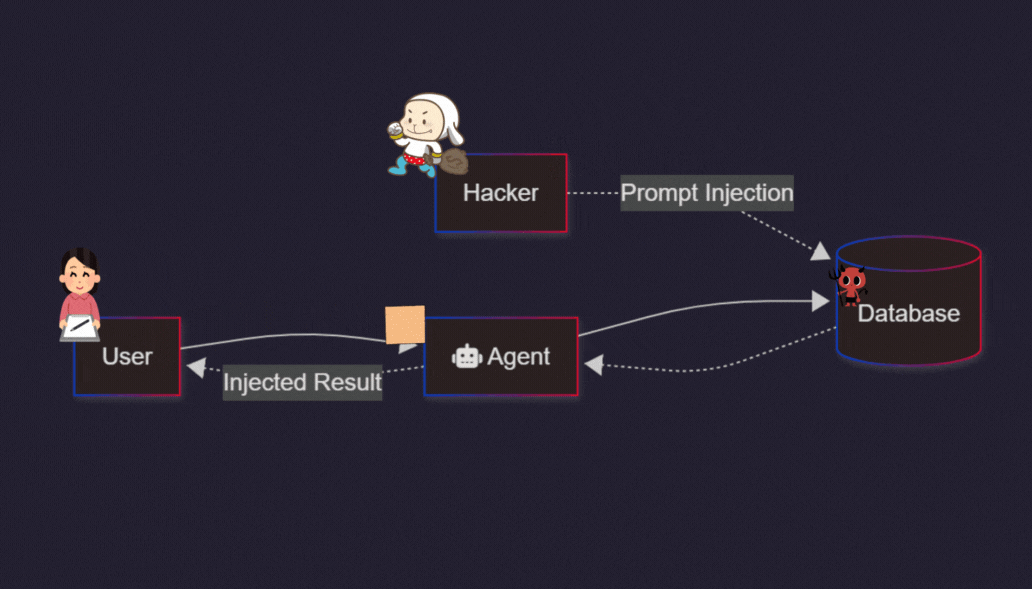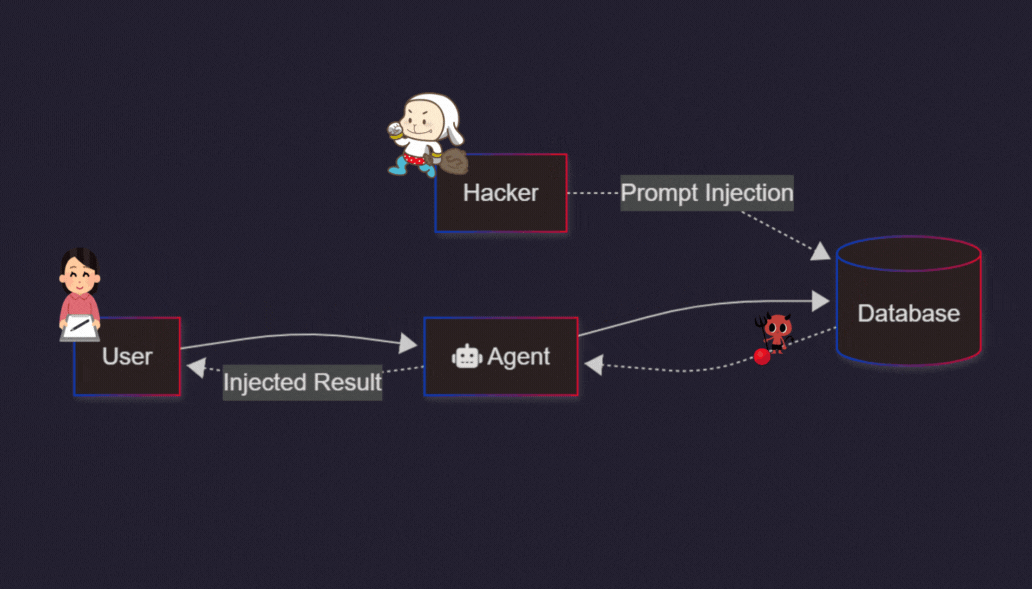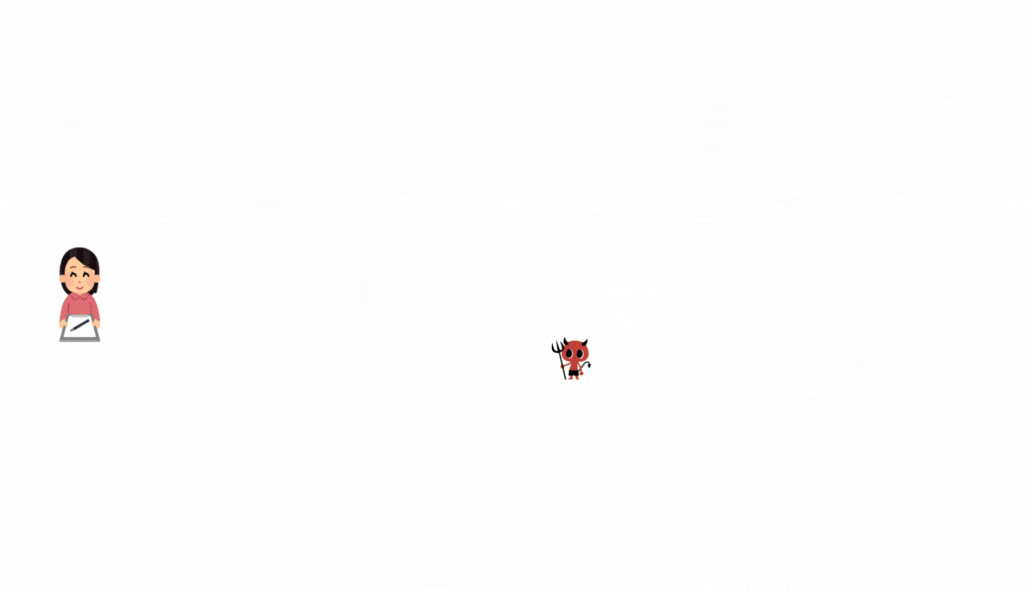
BUT the OTHER major ‘FOREVER PROBLEM’ in AI that gets less attention is PROMPT INJECTION. And it’s worth noting because it is an ‘AI Show-stopper’, especially as AI systems go from Chatbots to AI Reasoning and AI Agents as per the AI roadmap below:
Google Gemini’s AI Overview (vetted by me for hallucinations and prompt injections), provides the following summary on prompt injections, along with source links as needed:
“Prompt injection is the single most critical security vulnerability in the AI industry. Because large language models cannot inherently distinguish between system instructions and untrusted external data, attackers can easily hijack AI outputs, extract sensitive data, and manipulate agentic workflows. [1, 2, 3, 4]
“Why the Problem is “Deep”
“The “Confused Deputy” Flaw: The core architecture of LLMs is at fault. System prompts, retrieved RAG documents, and user inputs all share the same context window, making injection practically a design flaw rather than a software bug. [1]”
“The Rise of Autonomous Agents: With the shift toward agentic AI that executes real-world actions (e.g., querying databases, triggering API calls, or making payments), prompt injection is no longer just a text-misbehavior issue; it is a gateway to full system compromise. [1, 2, 3, 4, 5]”
“Indirect Prompt Injections: This is the most dangerous variant. Threat actors plant malicious instructions in websites, emails, or PDFs that the AI quietly ingests. The user acts completely normally, but the AI acts on the attacker’s hidden instructions embedded in the data. [1, 2, 3]”
“Massive Blast Radius: Major tech platforms have struggled with this, as demonstrated by well-publicized cases where attackers manipulated AI chatbots into handing over administrative access to high-profile accounts. [1]”
There are no easy or even hard fixes. And the industry is intensely trying.
“How AI Companies are Responding”
“Because no single patch can permanently fix prompt injection, AI companies and enterprise security teams rely on a multi-layered defense strategy: [1]”
“Privilege Separation: The most effective mitigation. AI agents are heavily sandboxed so they only possess the exact permissions required for their specific task, limiting the “blast radius” of any successful injection. [, 2]”
“Input Sanitization: AI companies use semantic attack detection layers to screen inputs for jailbreak patterns and malicious instructions before the request ever reaches the foundational model. [1]”
“Output Validation: Implementing guardrails and human-in-the-loop protocols so that high-risk AI decisions (such as executing financial actions) require explicit human approval. [, 2]”
“Framework Compliance: Organizations are aligning with NIST AI RMF 2.0 guidance to map AI security into enterprise risk management and governance. [1, 2]”
And both hallucinations and prompt injections compound exponentially as AI tech accelerates via scaling into AI reasoning, agents and beyond.
“OpenAI has begun rolling out Lockdown Mode, an optional security setting designed to offer users advanced protection from prompt injection attacks. For the unfamiliar, prompt injection is a form of social engineering that is specific to conversational chatbots. As AI systems have become better at pulling information from the internet, people have begun hiding malicious instructions on webpages and other places to try and trick those systems.”
“OpenAI is billing Lockdown Mode as a sort of last line of defense against prompt injections, building on the robust protections that it says it already offers through ChatGPT, its models and backend systems. “Lockdown Mode is not intended for everyone,” OpenAI explains. “It is designed for people and organizations that handle sensitive data and want stricter protection from data exfiltration risks related to prompt injection.”
The injections come from any multi-modal source, left brain or right. That fuels all AI systems with constantly changing internet and world data. Real and synthetic. The prompts can be inserted anywhere by anyone.
Not just ‘cyber-hackers’. But vetted parties on the internet for their own purposes and incentives. Like advertisers, as an example.
Note how the protection feature is essentially an ‘opt-in’ feature that shuts down most of the features of AI reasoning and agentic systems that are actually the features that most users want to use. By shutting them down competely and/or in part, means the user needs to do a ton of work in the beginning and throughout the system to essentially manually guard against AI prompt injections.
“To that end, enabling Lockdown Mode limits some of the features OpenAI offers through ChatGPT and its other products. For instance, you can still use image generation and upload photos to ChatGPT, but it may not pull images from the internet or display any images inside of a response. The chatbot also cannot download files to analyze, though you can still manually upload documents if you want its insight. Other features, such as Deep Research and Agent Mode are disabled completely. “Lockdown Mode does not change memory, file uploads, the ability to share a conversation, or whether your conversations may be used to improve models,” OpenAI adds. “Many of these settings are separately configurable by workspace admins.”
And opting in doesn’t solve the issue totally:
“The company also notes Lockdown Mode won’t stop prompt injections from appearing in content ChatGPT processes. Instead, it’s designed to prevent an attacker from extracting sensitive data from your account by limiting network requests that someone could exploit. Lockdown Mode is available to all personal accounts, including those using ChatGPT through OpenAI’s free tier. To activate it, open ChatGPT’s settings menu and select Safety and security. Under Advanced security, tap Lockdown mode and flip on the toggle. You can temporarily disable the additional protection by selecting Manage from the status message that appears above the chat window and selecting Turn off for this chat.”
And OpenAI along with their peers are trying other approaches as well:
“Separately, OpenAI is rolling out an active session manager that allows users to see any devices or browsers that have been used to access their account. From there, the company offers the option to log out of individual or all sessions at once. Just note the latter can take up to 30 minutes to complete. “If you suspect unauthorized account activity, change your password if you use one, review your sign-in methods, and contact OpenAI Support,” the company adds.”
Reassuring steps they think of course. And for good measure and reassurance, they add the following as well:
“The company says most users don’t need to use the feature.”
For those that want to delve into AI prompt injections in more detail, I’d highlight this piece in particular for how it lay out the complexity of these injections with simple candor. An example:
“Are you aware of Prompt injection attacks, Jailbreaking LLMs, AI agent hijacking, Data poisoning attacks, AI model manipulation, Adversarial AI attacks, Model poisoning, Evasion attacks, Prompt hijacking, Indirect prompt injection.”
The real reality is that prompt injections should be on the radar of all AI users, whether its for personal or work purposes. Especially as we ramp up our reliance on AI reasoning and agentic workflows next.
TGIF… Last week I wrote ‘is it time to panic’? My thesis is if you must panic, panic first. The week is now over and while the markets continue lower, it...
Good afternoon. Welcome to Trends with No Friends. For those just joining us, here’s an overview… Trends With No Friends sifts through the noise and...