
AI: 'Scaling AI' getting redefined. RTZ #537


A key assumption in the current rush to invest billions and trillions in ‘AI Compute’ infrastructure in this AI Tech Wave has been the idea that AI can be scaled indefinitely at levels exceeding Moore’s Law. Signals from the leading LLM AI companies like OpenAI, are indicating that the AI Scaling (with Trust preferably), may come in different forms than it has done so far in the two years since OpenAI’s ‘ChatGPT Moment’.
The Information outlines this in “OpenAI Shifts Strategy as Rate of ‘GPT’ AI Improvements Slows” walking through this ‘good news’ and the ‘bad news’ framing:
“The number of people using ChatGPT and other artificial intelligence products is soaring. The rate of improvement for the basic building blocks underpinning them appears to be slowing down, though.”
“The situation has prompted OpenAI, which makes ChatGPT, to cook up new techniques for boosting those building blocks, known as large language models, to make up for the slowdown.”
All this is ahead of OpenAI’s long-awaited GPT-5 LLM AI, code-named Orion as I’ve discussed before.
The Information continues:
“The challenges OpenAI is experiencing with its upcoming flagship model, code-named Orion, show what the company is up against. In May, OpenAI CEO Sam Altman told staff he expected Orion, which the startup’s researchers were training, would likely be significantly better than the last flagship model, released a year earlier.”
“Though OpenAI had only completed 20% of the training process for Orion, it was already on par with GPT-4 in terms of intelligence and abilities to fulfill tasks and answer questions, Altman said, according to a person who heard the comment.”
“While Orion’s performance ended up exceeding that of prior models, the increase in quality was far smaller compared with the jump between GPT-3 and GPT-4, the last two flagship models the company released, according to some OpenAI employees who have used or tested Orion.”
This is the reason for some of the questions on the current path to AI Scaling:
“The Orion situation could test a core assumption of the AI field, known as scaling laws: that LLMs would continue to improve at the same pace as long as they had more data to learn from and additional computing power to facilitate that training process.”
“In response to the recent challenge to training-based scaling laws posed by slowing GPT improvements, the industry appears to be shifting its effort to improving models after their initial training, potentially yielding a different type of scaling law.”
“Some CEOs, including Meta Platforms’ Mark Zuckerberg, have said that in a worst-case scenario, there would still be a lot of room to build consumer and enterprise products on top of the current technology even if it doesn’t improve.”
Thus the focus on using the new models in different ways:

“At OpenAI, for instance, the company is busy baking more code-writing capabilities into its models to head off a major threat from rival Anthropic. And it’s developing software that can take over a person’s computer to complete white-collar tasks involving web browser activity or applications by performing clicks, cursor movements, text typing and other actions humans perform as they work with different apps.”
“Those products, part of a movement toward AI agents that handle multistep tasks, could prove just as revolutionary as the initial launch of ChatGPT.”
And industry conviction to AI Scaling remains high with Meta’s Zuckerberg, xAI’s Musk and others:
“Furthermore, Zuckerberg, Altman and CEOs of other AI developers also publicly say they haven’t hit the limits of traditional scaling laws yet.”
“That’s likely why companies including OpenAI are still developing expensive, multibillion-dollar data centers to eke out as many performance gains from pretrained models as they can.”
That doesn’t mean that the leading researchers don’t debate the pros and cons:
“However, OpenAI researcher Noam Brown said at the TEDAI conference last month that more-advanced models could become financially unfeasible to develop.”
“After all, are we really going to train models that cost hundreds of billions of dollars or trillions of dollars?” Brown said. “At some point, the scaling paradigm breaks down.”
“OpenAI has yet to finish the lengthy process of testing the safety of Orion before its public release. When OpenAI releases Orion by early next year, it may diverge from its traditional “GPT” naming convention for flagship models, further underscoring the changing nature of LLM improvements, employees said. (An OpenAI spokesperson did not comment on the record.)”
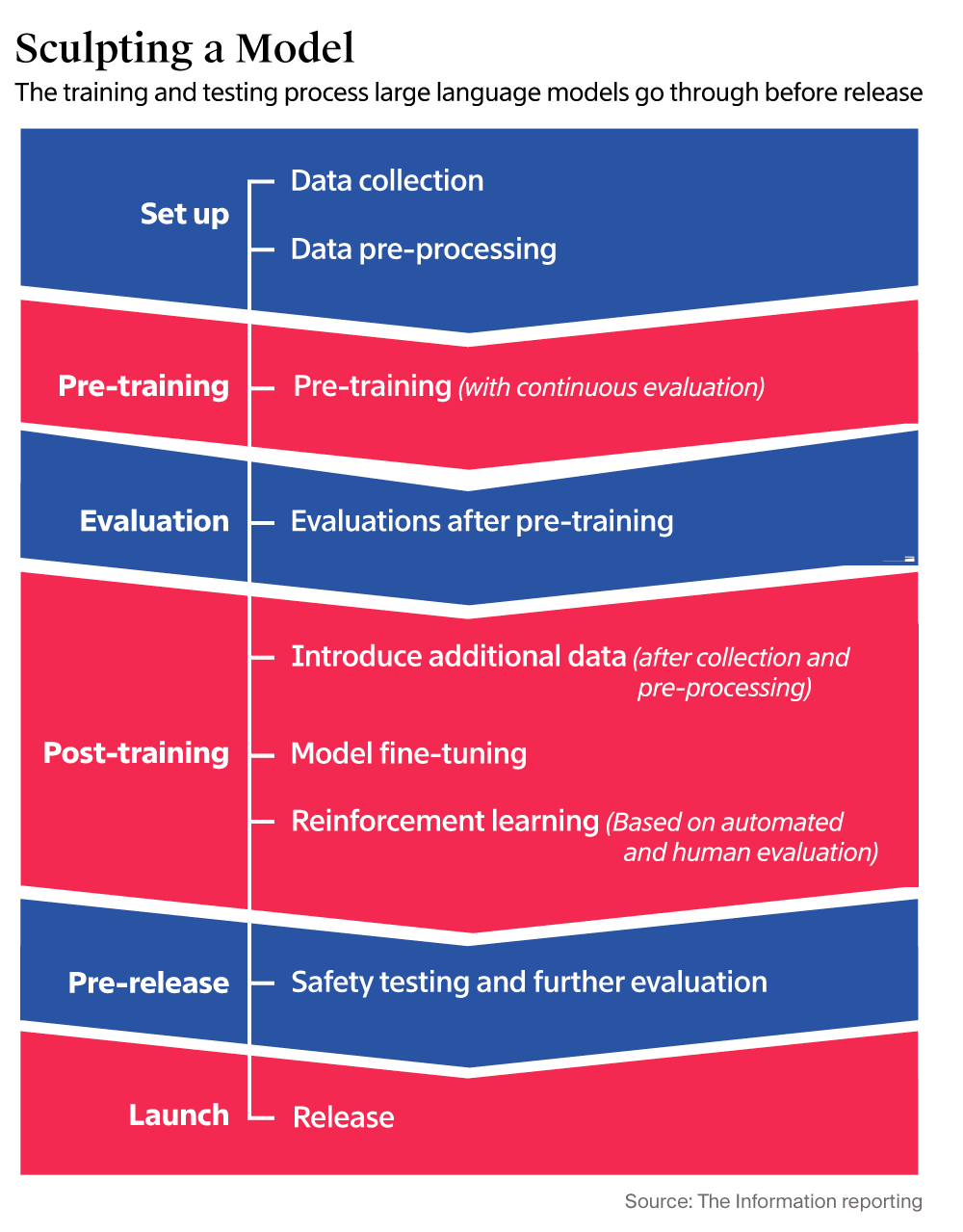
OpenAI currently is nearer the bottom of its GPT-5 model development process.
Then there of course is the issue of Scaling Data, something I’ve discussed at legnth:
“Hitting a Data Wall”
“One reason for the GPT slowdown is a dwindling supply of high-quality text and other data that LLMs can process during pretraining to make sense of the world and the relationships between different concepts so they can solve problems such as drafting blog posts or solving coding bugs, OpenAI employees and researchers said.”
“In the past few years, LLMs used publicly available text and other data from websites, books and other sources for the pretraining process, but developers of the models have largely squeezed as much out of that type of data as they can, these people said.”
OpenAI is focusing on this head on”:
“In response, OpenAI has created a foundations team, led by Nick Ryder, who previously ran pretraining, to figure out how to deal with the dearth of training data and how long the scaling law will continue to apply, they said.”
“Orion was trained in part on AI-generated data, produced by other OpenAI models, including GPT-4 and recently released reasoning models, according to an OpenAI employee. However, such synthetic data, as it is known, is leading to a new problem in which Orion may end up resembling those older models in certain aspects, the employee said.”
I’ve discussed synthetic data and content as additional new tools in the LLM AI scaling game.

And the company is cleverly using AI process innovations to tweak the scaling approach on both the models and data:
“OpenAI researchers are utilizing other tools to improve LLMs during the post-training process by improving how they handle specific tasks. The researchers do so by asking the models to learn from a large sample of problems—such as math or coding problems—that have been solved correctly, in a process known as reinforcement learning.”
“They also ask human evaluators to test the pretrained models on specific coding or problem-solving tasks and rate the answers, which helps the researchers tweak the models to improve their answers to certain types of requests, such as writing or coding. That process, called reinforcement learning with human feedback, has aided older AI models as well.”
And there is an ecosystem of AI companies helping figure out the right approaches at scale:
“To handle these evaluations, OpenAI and other AI developers typically rely on startups such as Scale AI and Turing to manage thousands of contractors.”
“In OpenAI’s case, researchers have also developed a type of reasoning model, named o1, that takes more time to “think” about data the LLM trained on before spitting out an answer, a concept known as test-time compute.”
I’ve discussed the importance of OpenAI’s o1 reasoning models:

“That means the quality of o1’s responses can continue to improve when the model is provided with additional computing resources while it’s answering user questions, even without making changes to the underlying model. And if OpenAI can keep improving the quality of the underlying model, even at a slower rate, it can result in a much better reasoning result, said one person who has knowledge of the process.”
“This opens up a completely new dimension for scaling,” Brown said during the TEDAI conference. Researchers can improve model responses by going from “spending a penny per query to 10 cents per query,” he said.”
Again, those costs too are on a rapid downward trajectory with software and hardware efficiencies, many led by industry leader Nvidia:
“Altman, too, has emphasized the importance of OpenAI’s reasoning models, which can be combined with LLMs.”
“I hope reasoning will unlock a lot of the things that we’ve been waiting years to do—the ability for models like this to, for example, contribute to new science, help write a lot more very difficult code,” Altman said in October at an event for app developers.”
Leading VCs like Andreessen Horowitz and other are noticing this shift in the Scaling Race:
“Some investors who have poured tens of millions of dollars into AI developers have wondered whether the rate of improvement of LLMs is beginning to plateau.”

“Ben Horowitz, whose venture capital firm is both an OpenAI shareholder and a direct investor in rivals such as Mistral and Safe Superintelligence, said in a YouTube video that “we’re increasing [the number of graphics processing units used to train AI] at the same rate, but we’re not getting the intelligent improvements at all out of it.” (He didn’t elaborate.)”
“Horowitz’s colleague, Marc Andreessen, said in the same video that there were “lots of smart people working on breaking through the asymptote, figuring out how to get to higher levels of reasoning capability.”
The video discussion, as well as the Information piece are both watching and reading in full for the nuance of this discussion.
So the Information’s eye-catching headline “OpenAI Shifts Strategy as Rate of ‘GPT’ AI Improvements Slows”, in my view can be reframed as
“OpenAI finds new ways to Scale AI with more Compute, on way to AGI”.
As I said in yesterday’s’Bigger Picture’:
“We may find over the next few years that the road to truly useful AI, are MANY AI models of ALL SIZES in this AI Tech Wave.”
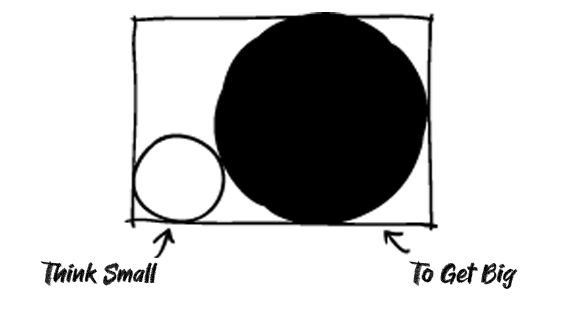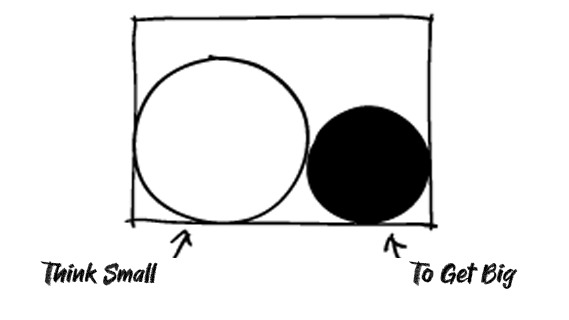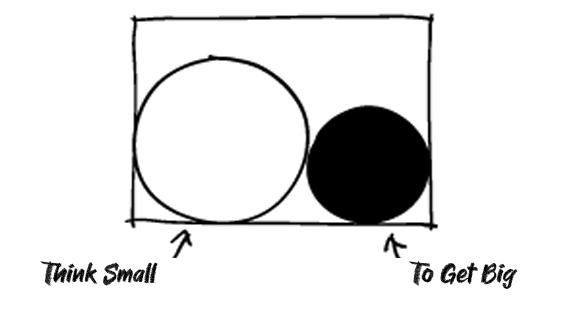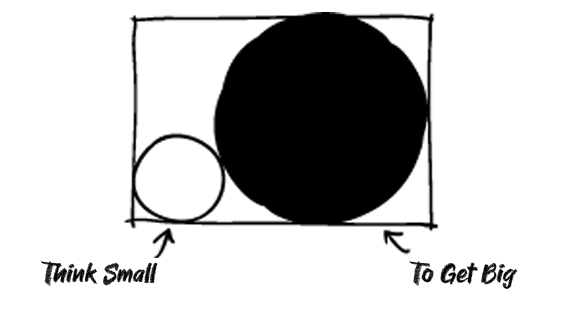
“Potentially almost as countless as the transistors in our devices today. Not to mention the countless ‘Teraflops’ and ‘Tokens’ of compute through these models of all sizes. All to answer the biggest and smallest questions by 8 billion plus humans. To get us closer to the ‘smart agents’ and ‘AI Reasoning’ that we’re all craving. Including our robots and cars to come.”
“It’s important to remember that it’s not just about billions and trillions of dollars for ever growing AI Compute, but billions and trillions of far smaller and tinier AI models on local devices, that get us closer to AI applications that truly delight and surprise mainstream users on the upside.”
Scaling AI is going to come in all forms of AI processes and sizes.
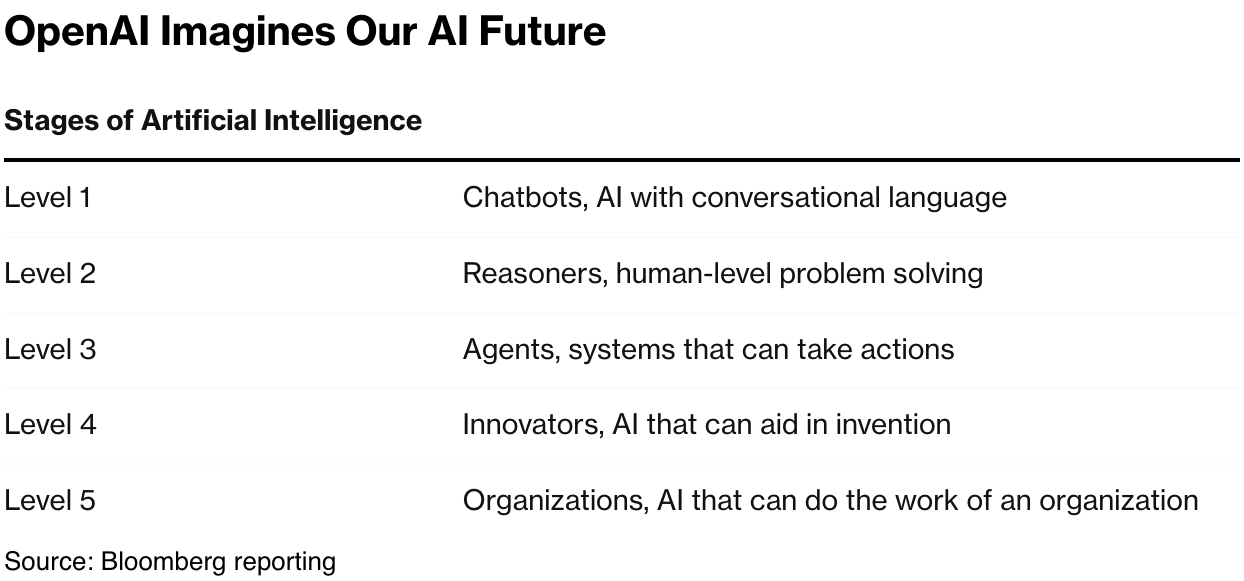
We need to expand our mental frameworks accordingly. OpenAI Sam Altman’s compass is pointing in the right direction. AGI however defined, is the general destination, with the chart above as the current map to ‘X’.

The paths to the destination via AI Scaling with massive Compute, may shift, fork, twist, and turn. But the destination remains the same.
OpenAI, Anthropic and others are figuring it out with flexibility. Stay tuned.
(NOTE: The discussions here are for information purposes only, and not meant as investment advice at any time. Thanks for joining us here)

