
AI: The '100,000 AI GPUs' Table Stakes opening round. RTZ #477

In my piece this Sunday ‘The new AI ‘Table Stakes’, this AI Tech Wave, I highlighted the escalating race on so many AI metrics for tech companies big and small :
“As we go into the Fall of 2024, just two months shy of the second anniversary of OpenAI’s ‘ChatGPT moment’ of November 2022, the ‘Table Stakes’ in this AI Tech Wave have gone way up for the top LLM AI players. And contrary of consensus, it’s not just the tens of billions of AI infrastructure capex per company. It’s increasingly the collection of top features and capabilities of the top LLM AI platforms.”

One of the clearest near-term metrics of these new ‘Table Stakes’ is getting to an AI data center that fields over 100,000 AI GPUs. Where the chips alone cost billions.
Most of the time they’re from Nvidia, if their founder/CEO Jensen Huang ends up allocating those $30,000 plus per chip prizes in sufficient quantities and on time. As I’ve noted several times, the key companies at the front of the allocation line remain Microsoft/OpenAI, Meta, Amazon, Google, Oracle amongst others.
With the exception of Meta, the others are fielding these chips in AI data centers old and new for BOTH their own AI product initiatives, AND for their enterprise facing AI Cloud businesses.
It of course just starts with the AI GPU chips.
There’s fierce, ‘emotional’ competition out there for Nvidia’s scarce Blackwell chip supply. As Bloomberg outlines in “Nvidia CEO Says Customer Relations are ‘Tense’ due to Shortages’”:
“‘We probably have more emotional customers today,’ he says.”
“Nvidia chips have become essential ingredient for the AI boom”

“CEO Jensen Huang, whose products have become the hottest commodity in the technology world, said that the scramble for a limited amount of supply has frustrated some customers and raised tensions.”
“The demand on it is so great, and everyone wants to be first and everyone wants to be most,” he told the audience at a Goldman Sachs Group Inc. technology conference in San Francisco. “We probably have more emotional customers today. Deservedly so. It’s tense. We’re trying to do the best we can.”
“Huang’s company is experiencing strong demand for its latest generation of chips, called Blackwell, he told the audience. The Santa Clara, California-based business outsources the physical production of its hardware, and Nvidia’s suppliers are making progress in catching up, he said.”
The piece goes into more detail on the challenges of managing this incoming demand for chip allocations.

Right now, it’s Meta’s turn to tout their Nvidia chip supply.
This week saw Meta highlighting they’re now approaching the 100,000 AI GPU mark, as the Information explains in “Meta will soon get a 100,000 GPU Cluster Too”:
“If an artificial intelligence developer doesn’t have a cluster of 100,000 Nvidia H100 server chips for training large language models, do they even exist?”
‘“All kidding aside, the AI data center race is in full swing as the six or so richest developers and cloud providers seemingly try to one-up each other on a weekly basis in terms of the size of their upcoming clusters.”
“We’ve learned that Meta Platforms is putting the final touches on one such cluster, which will be a little bigger than 100,000 H100s, located somewhere in the U.S. The company will use the new supercomputing cluster to train the next version of its Llama model—Llama 4, for those of you who are counting—according to a person at the company who is involved in the effort. The cost of the chips alone could be more than $2 billion! (We’ve added it to our database of 18 major AI data centers.)”

The running joke in Silicon Valley is that if Nvidia’s Jensen Huang shows up with the CEO of a Big Tech company on Stage at a conference of their choice, it’s usually because Nvidia is getting at least a billion dollar order for Nvidia AI GPUs and infrastructure. Their expense is Nvidia’s revenues.
The other metaphor of course is that in a gold rush, the surest near-term beneficiaries are the sellers of pick axes and shovels.

Meta’s Llama 4 of course is the expected next-generation open source LLM AI from Meta, championed by Meta founder/CEO Mark Zuckerberg laser-focused on various AI opportunities ahead. It’ll follow their ground-breaking 405 billion parameter large Llama 3.1 which is denting the world of LLM AIs so far in 2024. I’ve discussed Meta’s rollout of Nvidia AI GPUs in large quantities before, as the Information continues:
“The previously unreported cluster, which could be fully completed by October or November, comes as two other companies have touted their own. Last week, Elon Musk sparked a frenzy after saying he’d strung together a cluster that big in just a few months.”
“And earlier this week, Oracle co-founder Larry Ellison claimed to have an 800 megawatt data center, but the company won’t have a 100,000-chip cluster up and running until next year, and even then a cluster of that size would not require 800 megawatts of power. (Meta’s only needs about 150 megawatts, the person involved with it tells us.) We also poked fun at Ellison in yesterday’s newsletter, as he went off on a tangent to imply Oracle was going to be involved in making $100 billion mega AI data centers.”

“In Meta’s case, there may be more substance. CEO Mark Zuckerberg said in an Instagram post in January that the company would have 350,000 H100s online by the end of the year. Including other GPUs, Meta would have the equivalent of 600,000 H100s in compute online by then, he said. That likely means other clusters are in the works.”
“While the size of one’s GPU cluster is important, it’s not everything. You can do the same amount of model training with a smaller cluster—you just need to do it for a longer period of time. So whether you have 70,000 or so H100s, as OpenAI has, or 100,000-plus, it may not make that much of a difference in the near term.”
“The counter argument is that time is of the essence, and at least several companies want to figure out the efficacy of 100,000-chip clusters so they can plan 1 million-GPU clusters down the line.”
I note all this because this 100,000 AI GPU ‘table stakes’ metric for ramping AI data centers with billions in AI capex, is but a down payment on much higher table stakes in 2025 and beyond. So far besides Meta, Elon with xAI/Grok/Tesla, Google, Amazon/Anthropic, Oracle and others, additional players like Apple will also be in the race for multi-hundred thousand AI GPU chip data center super clusters.
And these chip escalations for these AI data centers of course takes the power consumption per data center from tens and hundreds of megawatts, to gigawatt plus Data centers. And that will at times require adjacent nuclear power to keep the chips on. Amazon, Microsoft, Google, Meta and others are all rapidly focusing on these key priorities.
Amazon recently signed a recent $650 million deal in Pennsylvania for a 960 megawatt data center, powered by the Susquehanna nuclear plant which generates 2.5 gigawatts of power.

So millions of AI Chips from Nvidia and other semi conductor companies, will require billions more in Power investments, with a rising role for more Nuclear power plants both in the US, China and around the world.
China alone is racing to build over 20 new nuclear plants in the next decade, while the US is just ‘thinking’ through how to build more than the 94 it has today. Most of those were built decades ago. And the US nuclear ‘know-how’ and expertise on commercial nuclear plants is now behind overseas competitors in China, South Korea, and elsewhere. The US has a thicket of regulatory issues to navigate through both at the federal and state levels, across multiple industries, just to begun to throw a nuclear switch on for now.
As an aside, the Bg2Pod by Bill Gerstner and Bill Gurley, published a well-researched video on that front, that is well worth watching in full. They visited and analyzed the Diablo nuclear plant in California that is in the process of being re-commissioned. It’s a good look at the opportunities and challenges ahead for the US to get going on commercial nuclear energy again.

Also worth perusing are the accompanying reference notes and links. (Kudos from one analyst to two others).

Coming back to near-term AI priorities, I discussed yesterday how OpenAI alone is racing on a range of LLM AI innovations and initiatives that each will require AI GPU clusters in the multiple hundreds of thousands.
The variable costs of billions of mainstream users (businesses AND consumers), using AI products and services in Box 6 below, are going to require AI training and inference compute that will require many multiples of these 100,000 AI GPU clusters being announced with fanfare today.

We’re likely to see each of the major players soon talk about million AI GPU data centers soon, which likely will be strung together across multiple facilities across many states soon, at investments in the tens of billions per company.
This piece by SemiAnalysis goes into the details of the technical challenges and complexities of these efforts, not the least of it at initiatives to provide sufficient Power and Cooling to these facilities. And that it takes years to get them in place, with the assistance of dozens of companies across several tech industries, up and down the AI Tech Stack below, from Boxes 1 through 5. Add on top of course the rising costs of AI Talent both direct and indirect. Lots of inputs for ‘AI Table Stakes’.
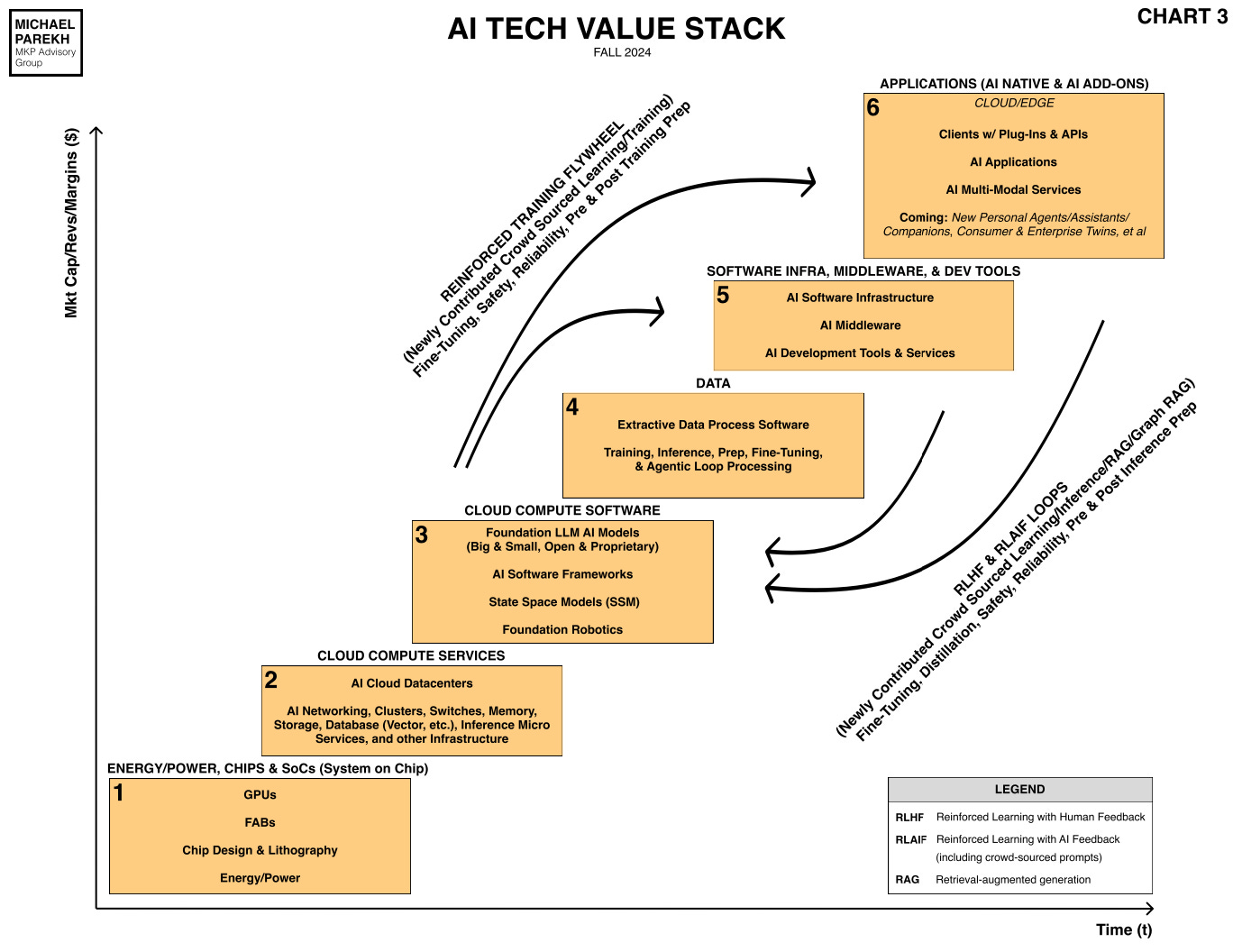
Hopefully, the above starts to explain why Nvidia’s Jensen Huang reminds us that there’s likely a trillion plus dollar investment race for AI data centers this decade.
And all this is of course all in advance of anticipated financial rewards and returns from customers down the road, and how those two cash flow streams will likely NOT be synced.
But it’s important to note the milestones in these increasing AI Table Stakes, and the 100,000 AI GPU super clusters are just the beginning in this AI Tech Wave. Stay tuned.
(NOTE: The discussions here are for information purposes only, and not meant as investment advice at any time. Thanks for joining us here)


