
AI: Value of Premium Content for Scaling AI models. RTZ #532


I’ve long discussed the accelerating trend for content deals in this AI Tech Wave. Particularly for the multimodal LLM AI companies to increasingly sign up content deals for their rapidly scaling models.
Ever increasing Data, including News, to train Generative AI models and their reinforcement learning and inference loops, is the unique part of the AI Tech Stack, that didn’t exist in prior tech waves like PC, Internet, Mobile and others. It’s Box #4 in the chart below, including critical sources like Wikipedia, Reddit and many, many others. And that’s going to see rapid changes with AI generated ‘Synthetic Data’, and attendant regulatory issues.
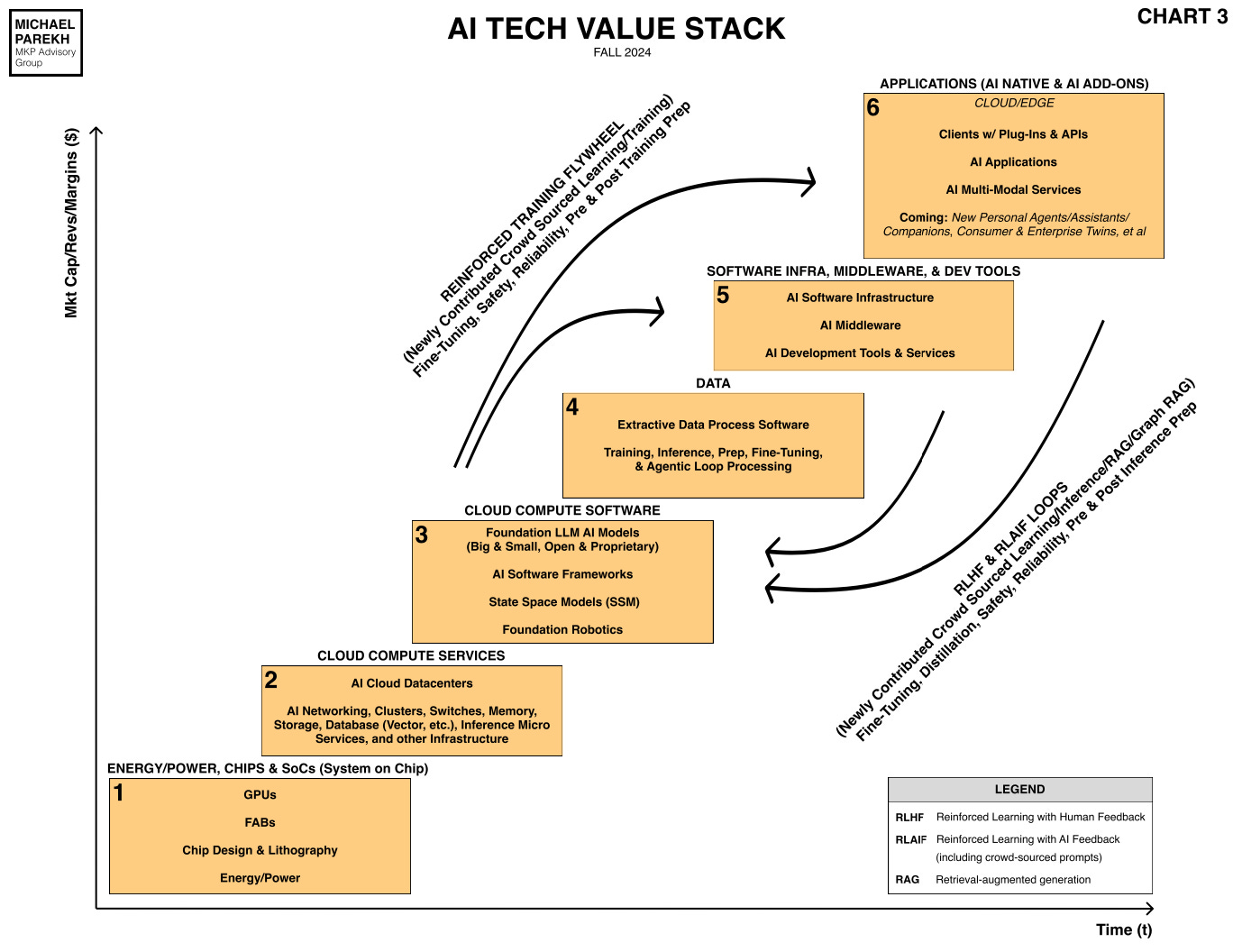
It’s Box #4 in the chart above, discussed before here in this “Show me the Money” post, and includes critical sources like Wikipedia, Reddit and many, many others.

So it’s helpful for both sides, the LLM AI model companies, and the content providers, to see new research that indicates the value of content from premium publishers to train LLMs. As Axios notes in “Ziff Davis study says AI firms rely on publisher data to train models”:
“Leading AI companies such as OpenAI, Google and Meta rely more on content from premium publishers to train their large language models (LLMs) than they publicly admit, according to new research from executives at Ziff Davis, one of the largest publicly-traded digital media companies.”
“Why it matters: Publishers believe that the more they can show that their high-end content has contributed to training LLMs, the more leverage they will have in seeking copyright protection and compensation for their material in the AI era.”

The problem of course is the opacity of what goes into the training models for the big LLM AI companies. They’re big businesses, so they guard the input details into their models like Coke guards it syrup formula:
“Zoom in: While AI firms generally do not say exactly what data they use for training, executives from Ziff Davis say their analysis of publicly available datasets makes it clear that AI firms rely disproportionately on commercial publishers of news and media websites to train their LLMs.”
-
“The paper — authored by Ziff Davis’ lead AI attorney, George Wukoson, and its chief technology officer, Joey Fortuna — finds that for some large language models, content from a set of 15 premium publishers made up a significant amount of the data sets used for training.”
-
“For example, when analyzing an open-source replication of the OpenWebText dataset from OpenAI that was used to train GPT-2, executives found that nearly 10% of the URLs featured came from the set of 15 premium publishers it studied.”
Of course Ziff Davis does have an agenda for its study at this time:
“Of note: Ziff Davis is a member of the News/Media Alliance (NMA), a trade group that represents thousands of premium publishers. The new study’s findings resemble those of a research paper submitted by NMA to the U.S. Copyright Office last year.”

-
“That study found that popular curated datasets underlying major LLMs significantly overweight publisher content “by a factor ranging from over 5 to almost 100 as compared to the generic collection of content that the well-known entity Common Crawl has scraped from the web.”
This training function is an ever increasing ‘flywheel’:
“Between the lines: The report also finds that a few public data sets used to train older LLMs are still being used today to train newer models.”
-
“The paper’s authors suggest the disproportionate reliance on premium publisher content to train older large language models extends to newer LLMs.”
-
“While those frontier models’ training is kept secret, we find evidence that the older public training sets still influence the new models,” the paper reads.”
The nature of the deals is also evolving:
“The big picture: Most news companies that are making deals with AI firms aren’t focusing on data training deals any more, since they tend to be one-time windfalls.”
-
“Instead, they are cutting longer-term deals to provide news content for generative AI-powered chatbots to answer real-time queries about current events.”
-
“A high-profile lawsuit brought by the New York Times against OpenAI and Microsoft could help define for the broader industry whether scraping publisher content without permission and using it to train AI models and fuel their outputs is a copyright violation.”

Of course sources like Rediff with a 100 million daily users, have already benefited from these trends with their recent licensing deal with OpenAI, relationship with Google, and their recent IPO. As the Information notes in “Why Reddit’s Explosive Growth Could Last”:
“Redditors may have their new favorite meme stock—Reddit.”
“The social media platform’s report of a 68% jump in third-quarter revenue sent the stock soaring 40% to around $115 last week, more than triple the price at which it went public in March. Reddit is now trading at a huge premium to other social media stocks—11.2 times next year’s estimated sales, compared to 7.7 times for Meta Platforms and 3.6 times for Snap, according to S&P Global Market Intelligence.”
And the company has barely expanded overseas:
”Another reason why investors can be confident that Reddit’s audience will continue to grow: It’s not yet a fully global service. The vast majority of content on Reddit’s site today is in English, executives say. But that is starting to change.”
But then overseas expansion has its own set of regulatory issues, as Wikipedia just found out in India:
“Wikipedia is facing mounting regulatory pressure in India as local authorities question whether the platform should continue to enjoy legal protections as a neutral intermediary rather than being classified as a publisher.”

“The Indian Ministry of Information and Broadcasting issued a notice to Wikipedia on Tuesday questioning the encyclopedia’s intermediary status that’s offered to tech platforms in India. The ministry cited concerns about concentrated editorial control and persistent complaints about bias and inaccuracies on the platform.”
“The notice follows a contentious case in the Delhi High Court, where judges have described Wikipedia’s open editing feature as “dangerous” and threatened to suspend its operations in India. The court is hearing a defamation case brought by news agency Asian News International, which seeks to identify Wikipedia contributors who allegedly characterized the news agency as a “propaganda tool” for India’s government.”
The company is trying to defend itself as a US based content provider:
“Justice Navin Chawla had dismissed Wikipedia’s plea for additional time to respond due to its lack of physical presence in India, warning of initiating contempt proceedings against the platform if it failed to comply with orders to disclose user information. “If you don’t want to comply with Indian regulations, then don’t operate in India,” the judge stated.”
I highlight these realities as the pluses and minuses of rapidly global social content businesses, even before meaningful introduction of AI capabilities.

And companies like Meta have that in their sights, as their recent deal with Reuters highlights. Especially with ‘Synthetic Content’ driven by AI that I recently discussed.
There are lots of twists and turns to come in AI Data via content and copyright providers in this AI Tech Wave. We are currently barely seeing the opening moves. Stay tuned.
(NOTE: The discussions here are for information purposes only, and not meant as investment advice at any time. Thanks for joining us here)



