
AI: Nvidia bolsters capabilities in AI Synthetic Data. RTZ #664


Nvidia followed up its very informative annual GTC conference keynote yesterday by founder/CEO Jensen Huang, with an acquisition in the ‘Synthetic Data’ space announced today. And it’s more important to their product roadmap than may seem on the surface. Would like to unpack that here today.
As Wired explains in “Nvidia Bets Big on Synthetic Data”:
“Nvidia has acquired synthetic data startup Gretel to bolster the AI training data used by the chip maker’s customers and developers.”

“The acquisition price exceeds Gretel’s most recent valuation of $320 million, the sources say, though the exact terms of the purchase remain unknown. Gretel and its team of approximately 80 employees will be folded into Nvidia, where its technology will be deployed as part of the chip giant’s growing suite of cloud-based, generative AI services for developers.”
“The acquisition comes as Nvidia has been rolling out synthetic data generation tools, so that developers can train their own AI models and fine-tune them for specific apps. In theory, synthetic data could create a near-infinite supply of AI training data and help solve the data scarcity problem that has been looming over the AI industry since ChatGPT went mainstream in 2022—although experts say using synthetic data in generative AI comes with its own risks.”
 / X")
Jensen provided the broader context for Data being critical to the Nvidia product roadmap ahead, at his keynote:
“During his keynote presentation at Nvidia’s annual developer conference this Tuesday, Nvidia cofounder and chief executive Jensen Huang spoke about the challenges the industry faces in rapidly scaling AI in a cost-effective way.”

“There are three problems that we focus on,” he said. “One, how do you solve the data problem? How and where do you create the data necessary to train the AI? Two, what’s the model architecture? And then three, what are the scaling laws?” Huang went on to describe how the company is now using synthetic data generation in its robotics platforms.”
Gretel potentially offers the ingredients to scale up solutions to this problem:
“Gretel was founded in 2019 by Alex Watson, John Myers, and Ali Golshan, who also serves as CEO. The startup offers a synthetic data platform and a suite of APIs to developers who want to build generative AI models, but don’t have access to enough training data or have privacy concerns around using real people’s data. Gretel doesn’t build and license its own frontier AI models, but fine-tunes existing open source models to add differential privacy and safety features, then packages those together to sell them. The company raised more than $67 million in venture capital funding prior to the acquisition, according to Pitchbook.”

“Unlike human-generated or real-world data, synthetic data is computer-generated and designed to mimic real-world data. Proponents say this makes the data generation required to build AI models more scalable, less labor intensive, and more accessible to smaller or less-resourced AI developers. Privacy-protection is another key selling point of synthetic data, making it an appealing option for health care providers, banks, and government agencies.”
It’s an area Nvidia has been laser focused on for some time:
“Nvidia has already been offering synthetic data tools for developers for years. In 2022 it launched Omniverse Replicator, which gives developers the ability to generate custom, physically accurate, synthetic 3D data to train neural networks. Last June, Nvidia began rolling out a family of open AI models that generate synthetic training data for developers to use in building or fine-tuning LLMs. Called Nemotron-4 340B, these mini-models can be used by developers to drum up synthetic data for their own LLMs across “autos, health care, finance, manufacturing, retail, and every other industry.”
The industry is already worried about running out of traditional data sources to train the LLM AI models going forward.
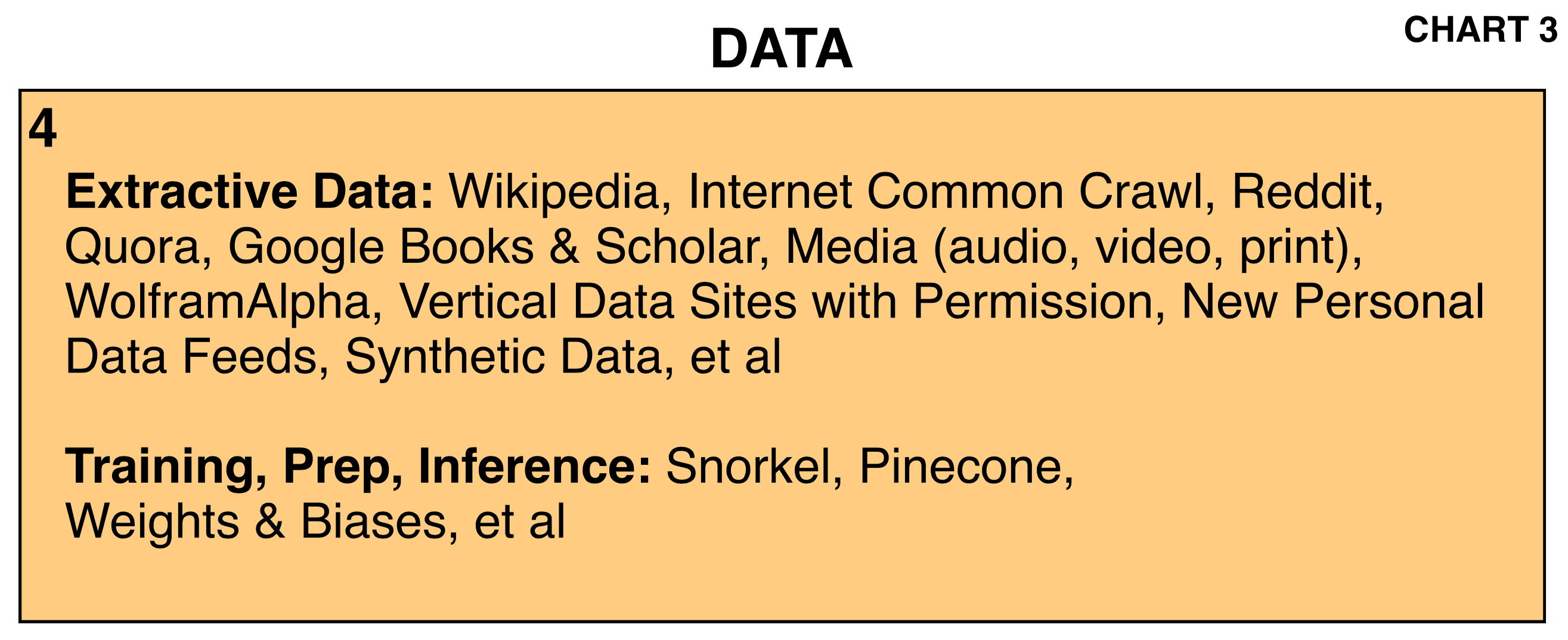
One of the solutions being focused on is ‘synthetic data’, where AI systems learn supervised and/or unsupervised from many forms of raw data like video files, new data to train the models going forward. And to run the inference calculations to answer exploding user prompts and questions.
So Synthetic data, along with ‘Synthetic Content’, is going to be important for every form of AI applications, not just LLM AI based, but in ‘physical AI’ applications involving self driving cars, robotics, and beyond.
The one way this AI Tech Wave is different than all the tech waves before it, is the critical role of Data driving the utility from AI applications and services over time. It’s Box no 4 in the AI Tech Stack I discuss often in these pages. And Box no. 5, which are the software tools that are critical to build the all important AI applications and services in the ‘holy grail’ Box no. 6 below.
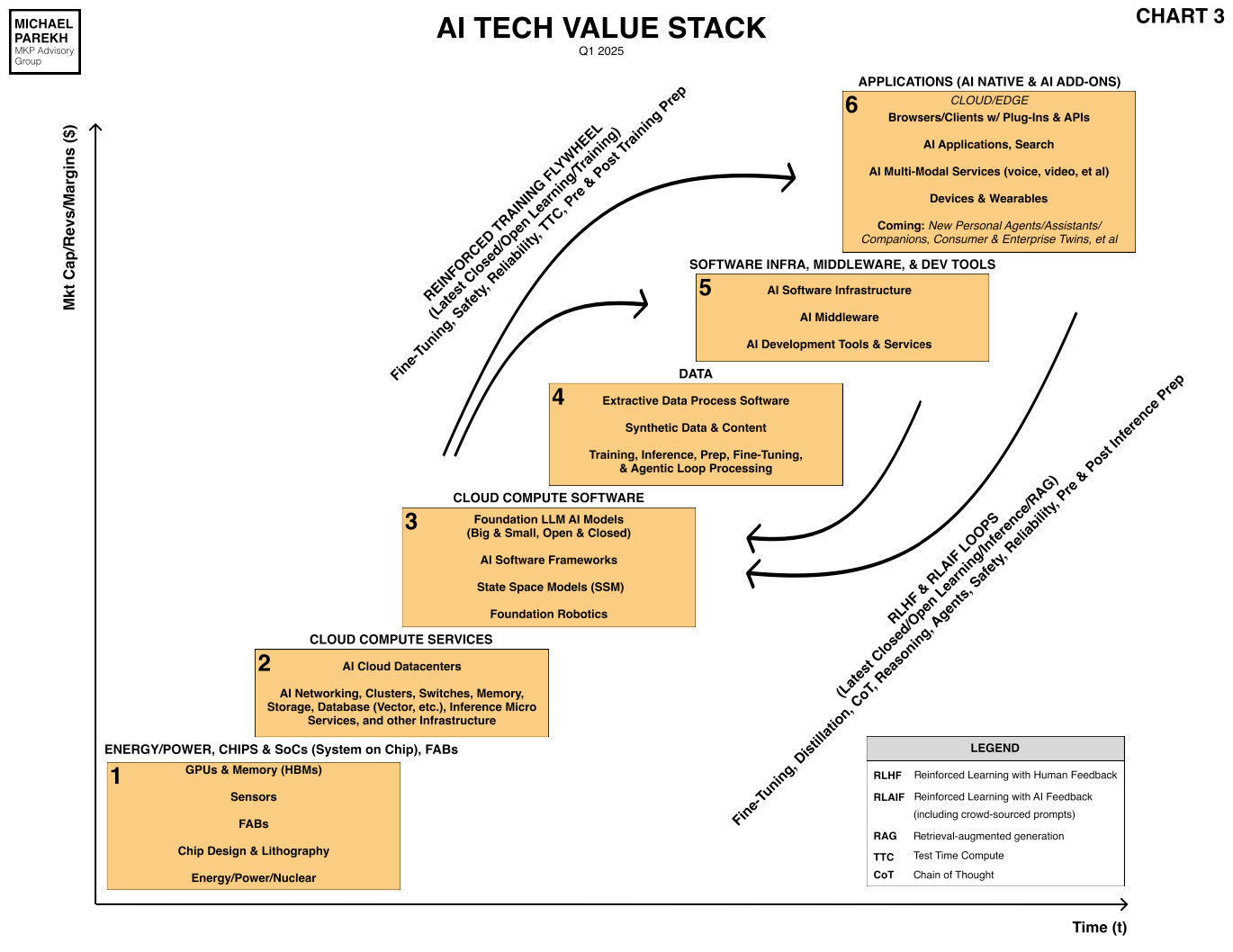
The importance of Data going forward for AI has been highlighted by industry luminaries like ex OpenAI founder Ilya Sutskever, who now is focused on that problem in novel ways with his unicorn startup Safe Superintelligence.

It’s a critical problem to solve if the industry is to execute through the next AI Reasoning and Agent levels towards AGI.
Nvidia is very focused on making data processing a key part of its hardware and software ecosystem, optimized for Inference calculation at ‘extreme computing’ scales I discussed yesterday.
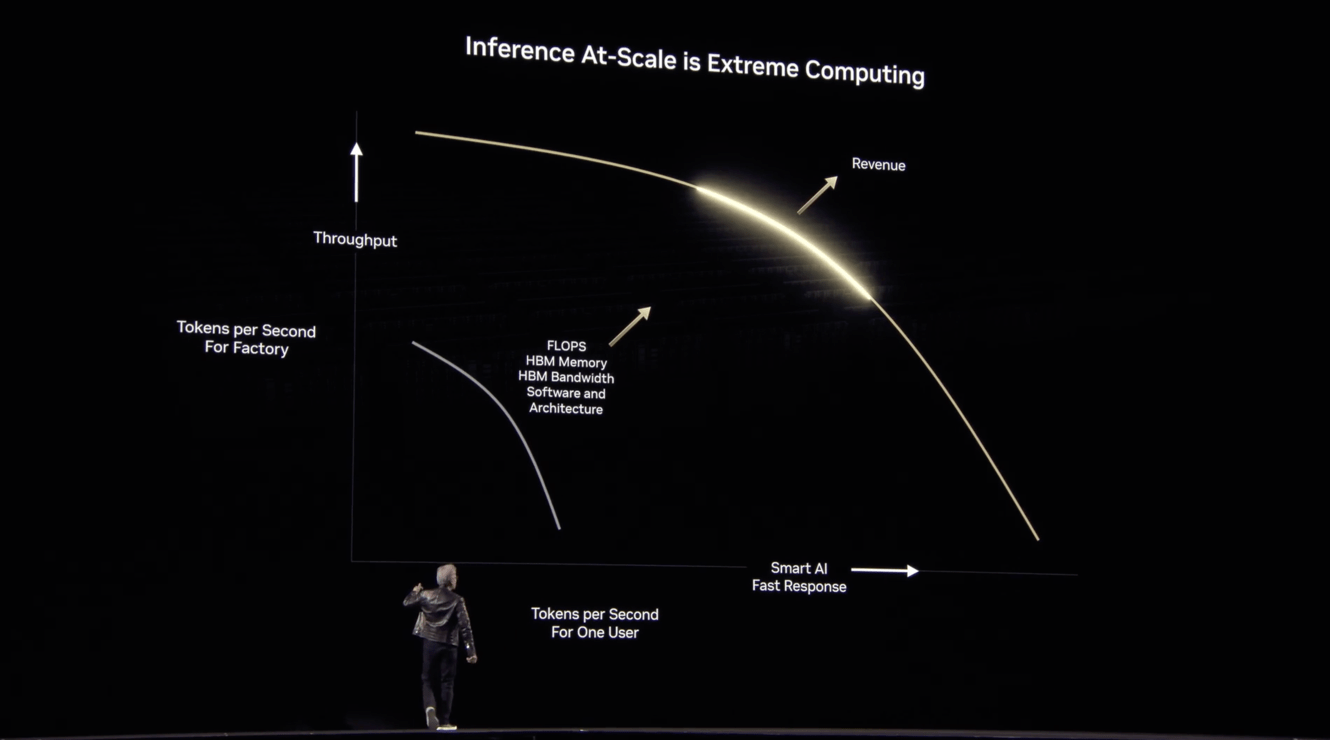
Nvidia’s acquisition of Gretel marks the importance of data as an inpur into ‘AI Factories’ (aka AI Data Centers), being built at the costs of hundreds of billinos in this AI Tech Wave. It’s thus useful to underline it importance at this early stage. Stay tuned.
(NOTE: The discussions here are for information purposes only, and not meant as investment advice at any time. Thanks for joining us here)



