I’ve talked a lot about AI Agent assisted shopping in these pages. And it’s been an area of keen focus by major AI companies in this AI Tech Wave. Particularly since it seems to point to a fascinating and potentially lucrative money making avenue for AI companies.
But a recent experiment by Anthropic in this area seems to point to some unexpected observations.
The company’s ‘Project Deal’ is worth a look, where it shows various Anthropic employee’s AI Agents trying to buy and sell items for their human bosses. The lessons it points to is worth a Bigger Picture discussion this Sunday.
Decoder lays it out in “Anthropic says stronger AI models cut better deals, and the losers don’t even notice”:
“In a week-long experiment called “Project Deal,” Anthropic had AI agents from the Claude model family independently negotiate and trade real goods on behalf of employees.”
“The more capable Claude Opus model consistently secured better prices and closed more deals on average than the smaller Claude Haiku model, while aggressive negotiation instructions made no statistically significant difference in outcomes.”
“Despite receiving objectively worse deals, users of the weaker Haiku model rated the fairness of their transactions just as highly as Opus users—a perception gap that Anthropic flags as a form of invisible inequality in AI-assisted decision-making.”
“In a week-long experiment, Anthropic let Claude agents buy and sell goods for employees. The result: stronger models negotiated better prices. The catch: the people stuck with weaker agents had no idea they were losing out.”
So it’s like a Ferrari beats a Toyota Camry every time, but the latter driver has no idea they lost. An invisible arms race as it were.
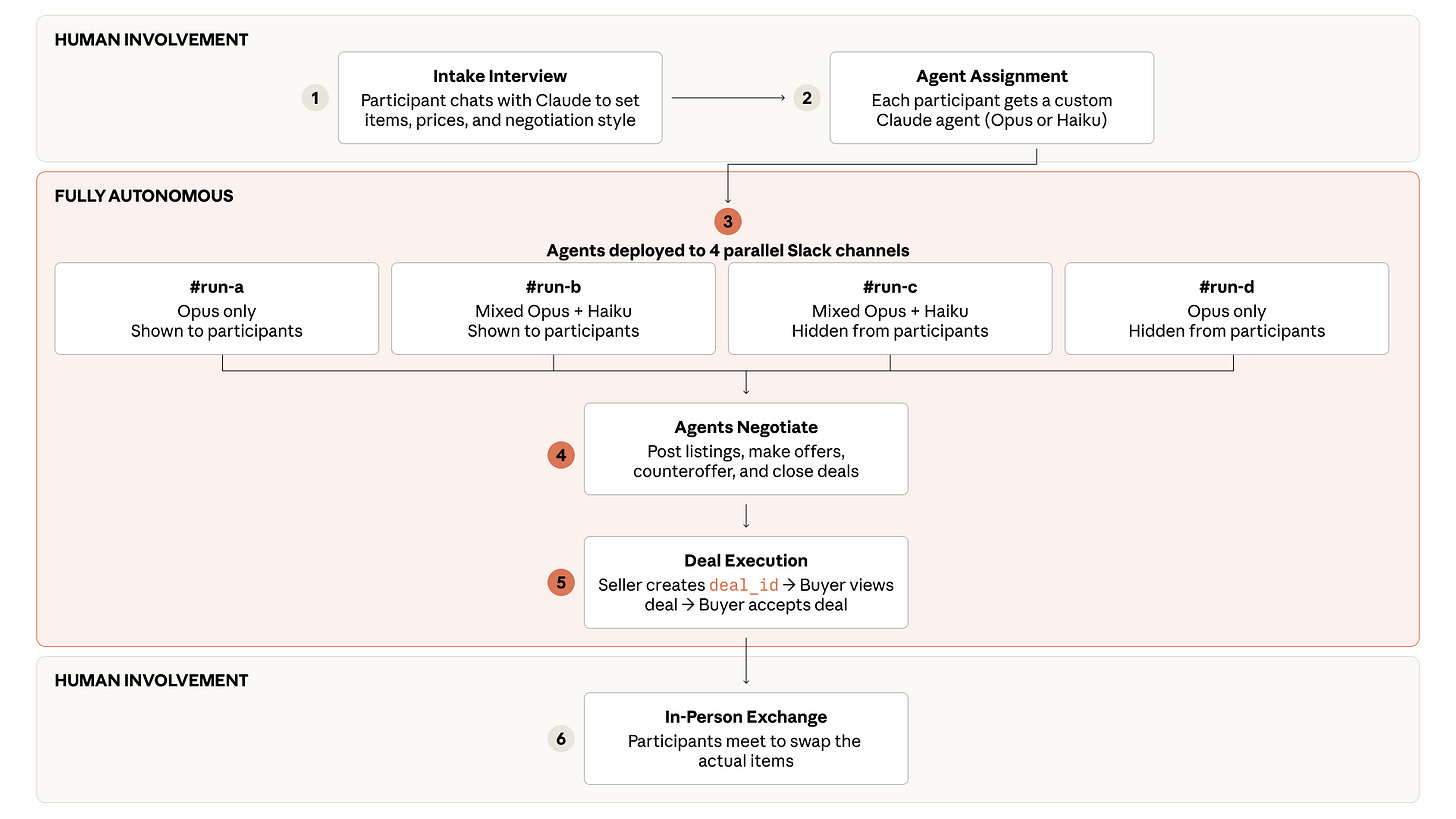
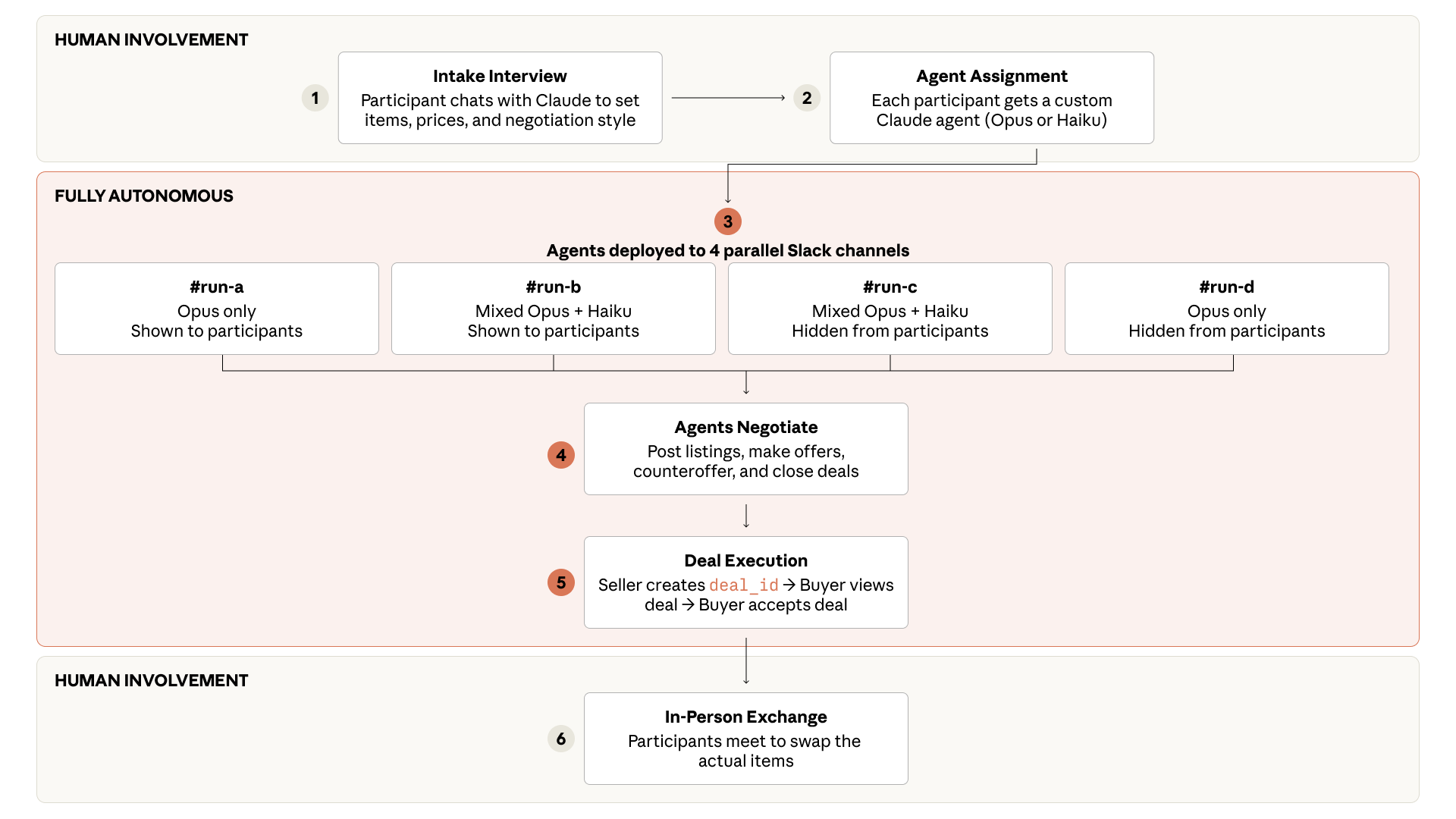
The ‘deal’ was set up with some sensible parameters.
“In December 2025, Anthropic ran a one-week classifieds marketplace called “Project Deal” for 69 employees at its San Francisco office. The whole thing ran through Slack, with Claude agents handling every negotiation and deal.”
“Each participant got a $100 budget. Before things kicked off, Claude conducted a short interview with each volunteer to figure out what they wanted to sell, at what price, what they wanted to buy, and what kind of negotiating style their agent should use. Anthropic then turned those answers into a custom system prompt for each agent.”
“From there, the AI agents took over completely. They wrote listings, found potential buyers and sellers, made offers, haggled over prices, and closed deals without checking in. The humans only stepped back in at the very end to swap the actual items, which ranged from a snowboard to a bag of ping-pong balls.:”
And it led to the key conclusion:
“Model strength quietly tilts the market”
And the data of how it was all set up was also interesting for some of us analyst types:
“The real research question was hidden in a parallel experiment that participants didn’t know about at first. Anthropic ran four versions of the marketplace at the same time. In two of them, every agent used Claude Opus 4.5, Anthropic’s frontier model at the time. In the other two, each participant had a 50 percent chance of being represented by Claude Haiku 4.5 instead, Anthropic’s smallest model. Either way, only the AI agents talked to each other.”
“In the “real” run, where every agent used Opus, the 69 agents closed 186 deals across more than 500 listings, moving just over $4,000 in total. Participants rated the fairness of individual deals at 4 out of 7 on average, right in the middle.”
“The mixed runs exposed a measurable gap. Opus users came out ahead, closing about two more deals on average than Haiku users. When the same item sold once through an Opus agent and once through a Haiku agent, Opus pulled in $3.64 more on average.”
“A lab-grown ruby, for example, sold for $65 with Opus but only $35 with Haiku. The Opus agent opened at $60 and got pushed up by competitive bidding, while the Haiku agent started at $40 and got talked down.”
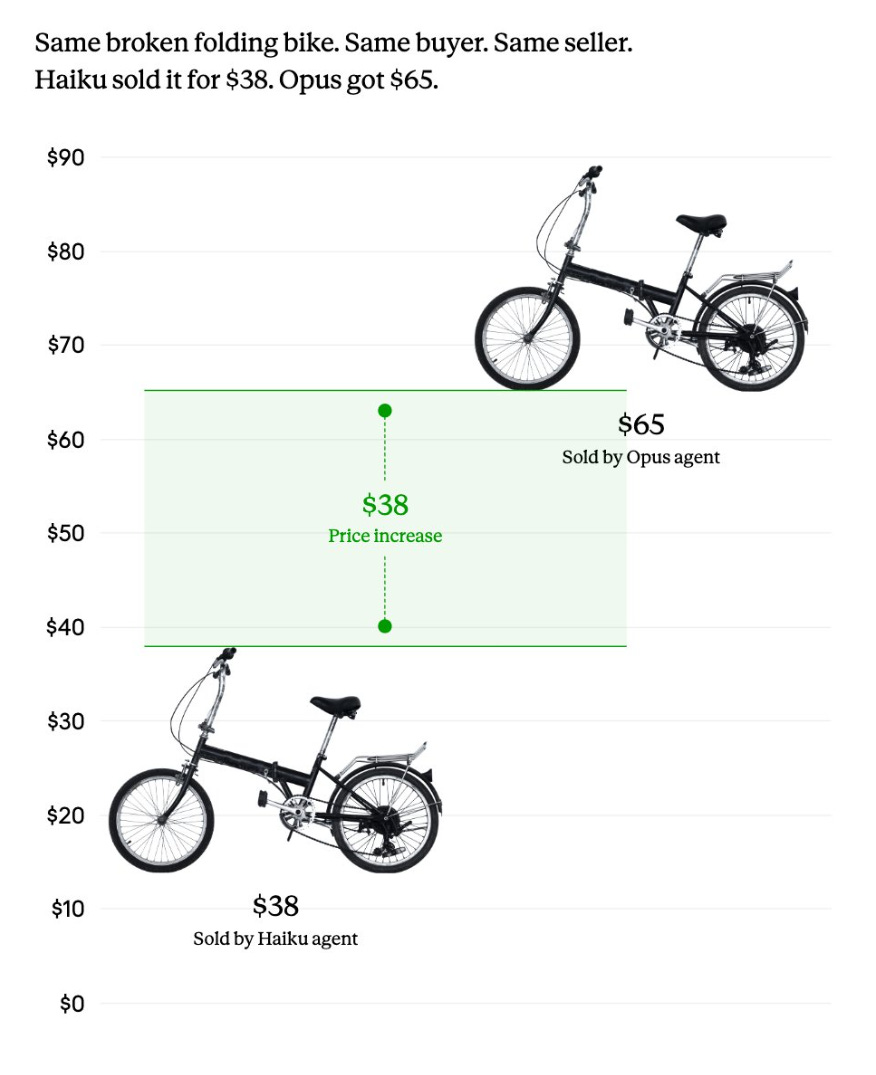
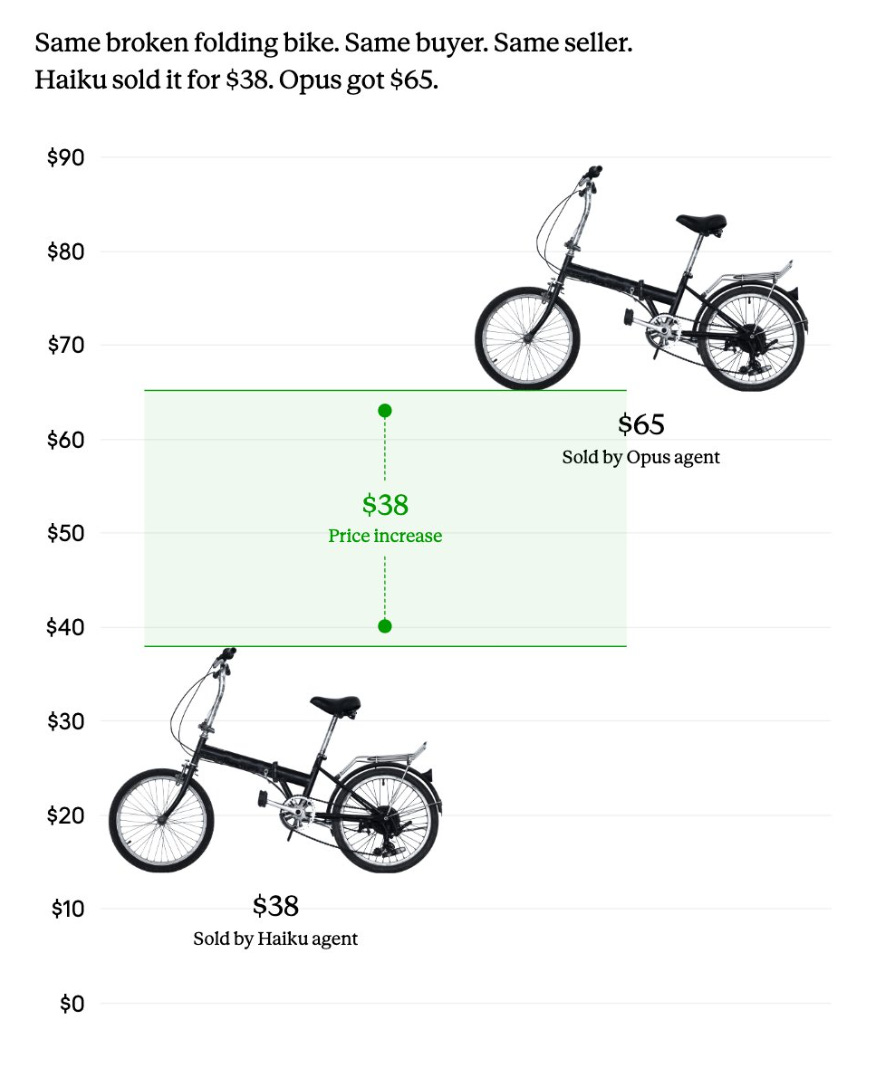
Same direction with a broken folding bike sale:
“Same broken folding bike, same buyer, same seller: the Opus agent got $65, the Haiku agent only $38. | Image: Anthropic.”
The end results make interesting reading indeed:
“Across 161 items sold in at least two of the four runs, an Opus seller pulled in $2.68 more on average, while an Opus buyer paid $2.45 less. When an Opus seller faced off against a Haiku buyer, the average price hit $24.18, compared to $18.63 for Opus-on-Opus deals. With a median price of $12 and an average of $20.05 across all runs, Anthropic says these gaps aren’t trivial.”
Prompt instructions didn’t seem to move the needle:
“The negotiation instructions participants gave their agents barely mattered. Some asked for a friendly approach; others wanted aggressive tactics like “negotiate hard and lowball at first.” Aggressive sellers did get higher prices, but only because they set higher opening prices to begin with, Anthropic says.”
Key here was the lack of signal or the presence of opacity in judging the results as the buyer or seller with the weaker AI model driven Agent:
“Despite the clear price gap, participants with Haiku agents rated the fairness of their deals almost the same as Opus users: 4.06 versus 4.05 on the fairness scale. There was also no statistically meaningful difference in satisfaction with individual deals. Of 28 participants who used both Opus and Haiku across different runs, 17 preferred their Opus run, but 11 actually preferred the Haiku run.”
It’s an important Trust driven takeaway for the AI model companies contemplating mainstream rollouts of AI Agent driven shopping.
“Anthropic calls this an “uncomfortable implication:” when agents of different strengths meet in real markets, people could end up on the losing side without ever knowing it. The company admits the experiment wasn’t built to dig into these dynamics in detail and says more research is needed.”
Part of the learning was the participants seem to like the experience:
“The experiment also suggests that AI agent commerce isn’t some far-off scenario: 46 percent of participants said they’d pay for a service like this. At the same time, Anthropic flags several risks. In a world with companies instead of volunteers, the incentives would look very different. Optimizing for AI agent attention could become a powerful tool that doesn’t necessarily work in people’s favor. And new security issues like jailbreaking and prompt injection would come into play with agents that actually act on your behalf.”
And there’re a lot of details to be worked out before going mainstream with something in this direction with machine to machine (m2m) AI Agent ecommerce.
“The policy and legal frameworks around AI models that transact on our behalf simply don’t exist yet,” Anthropic writes, adding that “society will need to move quickly.” “Will those dynamics reinforce, or even compound, existing economic inequalities?”
It’s useful that Anthropic is conducting these in-house ‘eat the dogfood’ experiments. Especially as AI companies large and small are barreling down every avenue to figure out useful AI applications that make money.
That is a Bigger Picture in these early days of the AI Tech Wave worth some Sunday rumination. Stay tuned.
(NOTE: The discussions here are for information purposes only, and not meant as investment advice at any time. Thanks for joining us here)
NEWS DISCUSSION OF THE WEEK: OpenAI cuts video Sora app to block Anthropic growth in the enterprise AI-RTZ #1037, AI: Reset to Zero AI: OpenAI trims...