As I’ve discussed at length in earlier posts. Now Google is advancing its TPU chip architecture to better execute both AI training and inference, with everything in between.
This is critical as AI applications move beyond AI chatbots to AI Reasoning, AI Agents and beyond.
“Alphabet Inc.’s Google Cloud division unveiled the latest generation of its tensor processing unit, or TPU, designed to make AI computing services faster and more efficient.”
“The new lineup comes in two versions, the TPU 8t for creating artificial intelligence software and the TPU 8i for running AI services after they’ve been created.”
“Google also announced a $750 million fund to help boost corporate AI adoption and showcased tools for building AI agents, including a dedicated inbox for virtual bots to post information and progress reports.”
“Alphabet Inc.’s Google Cloud division unveiled the latest generation of its tensor processing unit, or TPU, a homegrown chip that’s designed to make AI computing services faster and more efficient.”
“The new lineup will come in two versions, the company said Wednesday at its Google Cloud Next event, where it also announced a $750 million fund to help boost corporate AI adoption and showed off tools for building AI agents. The TPU 8t is tailored for creating artificial intelligence software, while the TPU 8i is designed to run AI services after they’ve been created — a stage known as inference.”
They then cover the broader competitive context:
“Google has emerged as one of the most successful makers of in-house AI chips in an industry dominated by Nvidia Corp. TPUs have become a hot commodity in Silicon Valley in recent months, and the company is looking to build on that momentum with the latest versions.”
“The effort is part of a broader push to make it cheaper and less energy-intensive to roll out AI software. The company also is working to make services more responsive. The new TPUs store more information on the chip, helping provide the rapid responses that users crave. But demands on increasingly complex layers of software are only growing.”
““It’s about how you deliver the lowest possible latency of the response at the lowest possible cost per transaction,” said Mark Lohmeyer, Google’s vice president of compute and AI infrastructure. “The number of transactions is going way up, and the cost per transaction needs to go way down for it to scale.”
The challenge is going up exponentially as more mainstream users figure out how to do more useful things with AI reasoning and agents, as I’ve discussed in detail.
“Creating AI services and software is done by using systems that can sift through massive amounts of data very quickly to make connections and establish patterns that can be represented mathematically. Inference, running the software and services, benefits from processors that have huge amounts of memory integrated into them.”
“This approach helps make AI responses more instantaneous because the component doesn’t have to go seek information stored elsewhere. It’s particularly useful when computers “reason” through problems, taking multiple steps and learning from their own actions.”
“The training chip, 8t, can be combined into groups of 9,600 semiconductors. Google said that when deploying such massive systems, power is increasingly the major constraint in data centers. Owners therefore need systems that are more efficient to get the best out of the limited availability of electricity. TPU 8t delivers 124% more performance per watt than the preceding generation, with TPU 8i providing a gain of 117%.”
Of course, CEO Sundar Pichai’s Google also offers its Google Cloud customers ample AI computing options with Nvidia GPU chips and hardware/software architectures:
“The company will continue to offer services based on Nvidia chips to customers who want to use the systems that currently dominate AI computing, it said. Google intends to be among the first to deploy gear based on a new design from Nvidia coming in the second half of the year, Lohmeyer said.”
“Like Google, Nvidia is focusing more on the inference stage of AI. Its forthcoming lineup will include technology from its acquisition of Groq — technology tailored specifically for providing ultrafast responsiveness.”
“Nvidia Chief Executive Officer Jensen Huang has said that more than 20% of AI workloads might be best served by that type of chip. Groq was founded in 2016 by a group of former Google engineers. Last December, Nvidia paid $20 billion for a license to use its technology and hired most of its engineering team.”
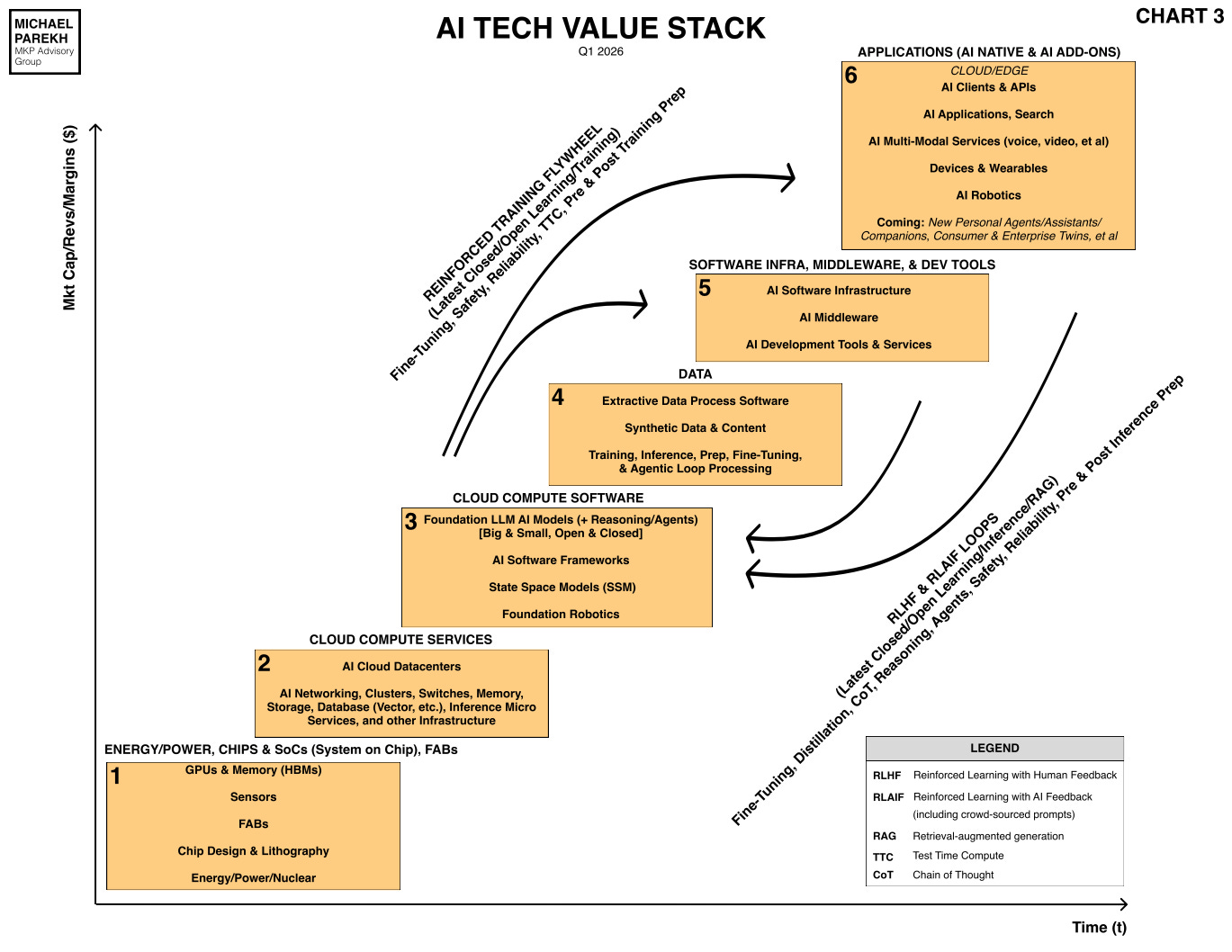
But for now it summarizes how Alphabet/Google, under CEO Sundar Pichai, is pressing on his core advantage vs peers in this AI Tech Wave. A fully vertical tech stack, down to the AI chips (Box 3), built at scale in fabs by TSMC (Box 1).
And while competitors from Amazon to Meta to OpenAI/Anthropic are doing the same, Google has several laps ahead of them all. WIth the only other company up front being Nvidia. Stay tuned.
(NOTE: The discussions here are for information purposes only, and not meant as investment advice at any time. Thanks for joining us here)
As a reminder, MarketSurge (by Investor’s Business Daily) is a sponsor of the weekly show. All the charts you have been seeing in the videos and will...