
AI: Lessons from Wikipedia on AI Data trends to come. RTZ #719

I’ve long written about how Data is the one distinctive element of this AI Tech Wave vs prior tech waves ike the PC, Internet, Cloud, Mobile and others. It’s Box no. 4 in the AI Tech Stack below, and is the fuel to both train AI models large and small, and also drive the inference ‘magic’ that drives the extraordinary results to endless user prompts and queries.
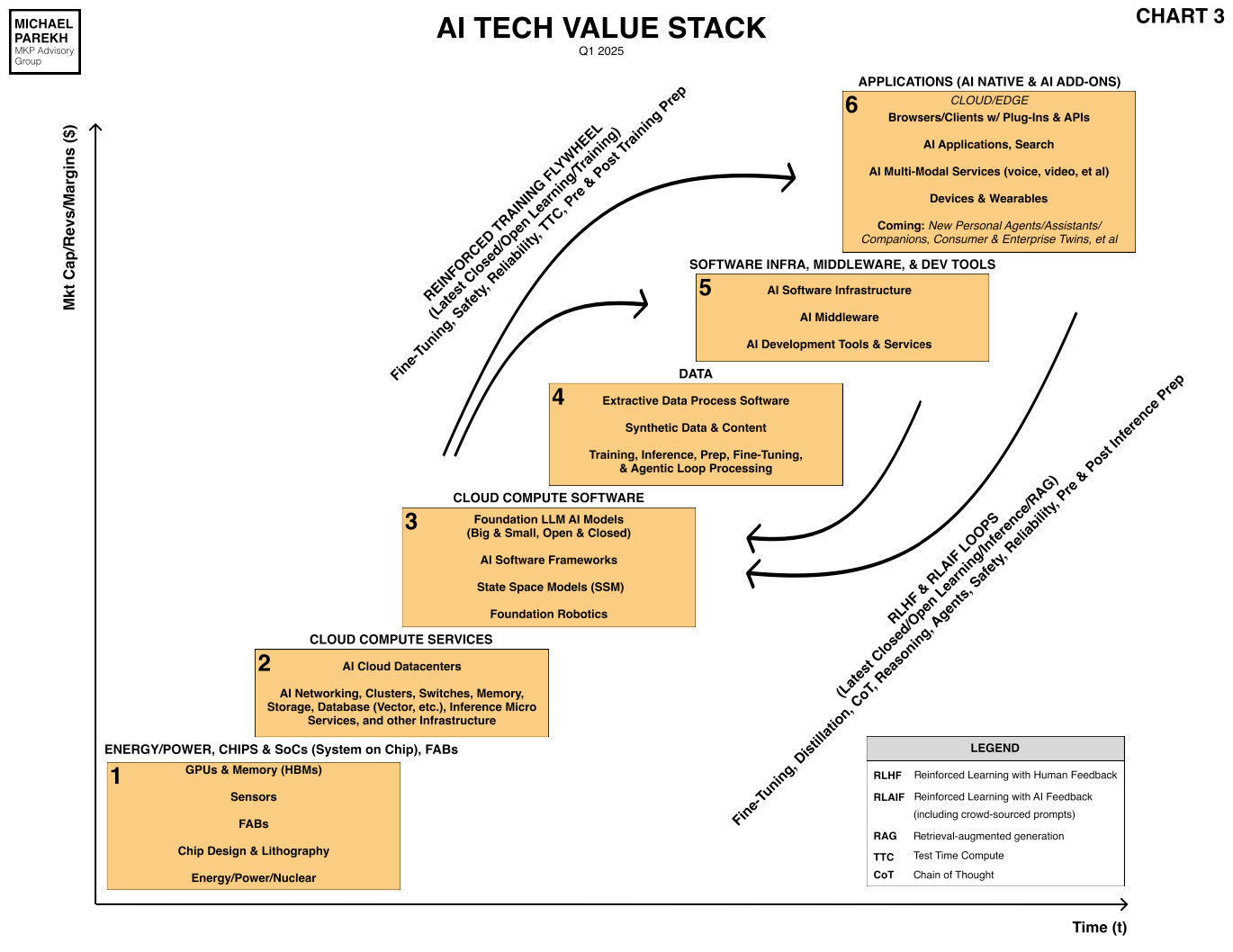
And in a close up of that Box no. 4 Data box always shows ‘Wikipedia’ as the archetypal type of data that gave us OpenAI’s ‘ChatGPT moment’ over two years ago.
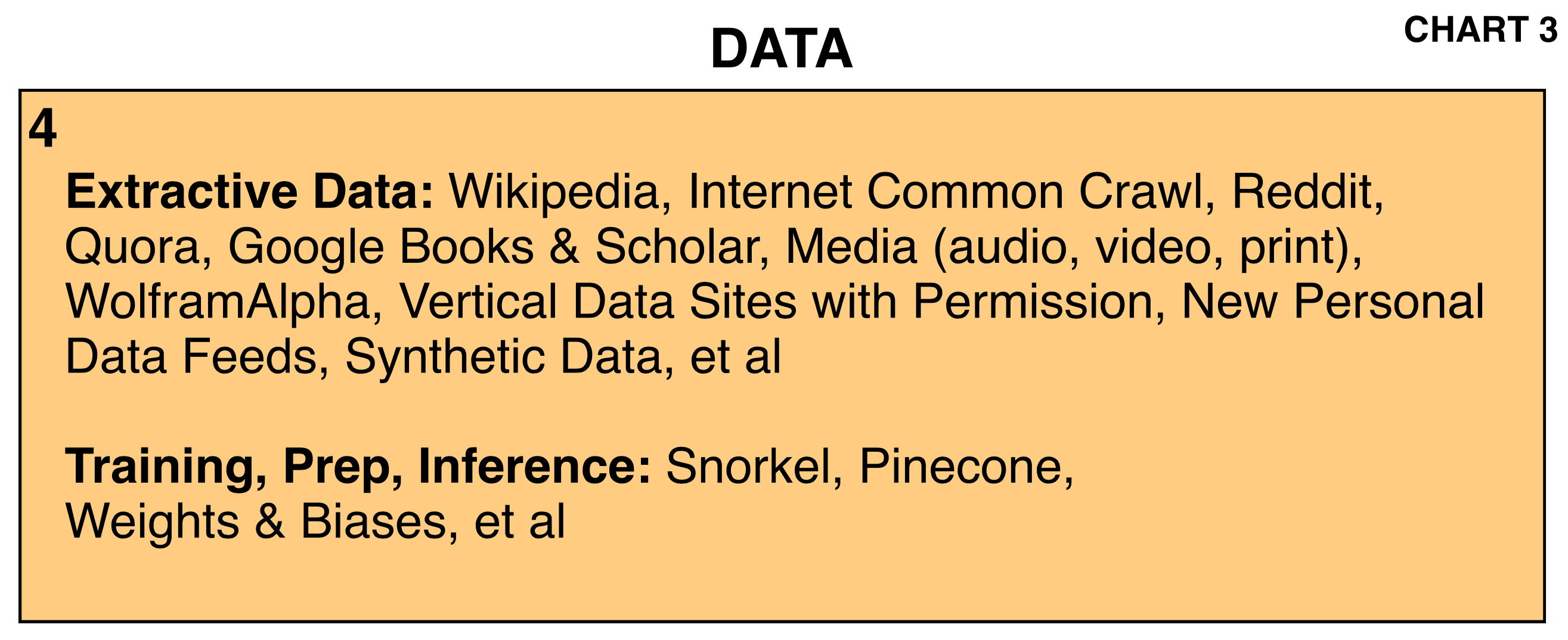
That then unleashed the world’s obsession to invest hundreds of billions annually to build AI data centers and infrastructure, to then generate the ‘Intelligence Tokens’ that make ‘AI’, AI.
Of course, many other data sources like Rediff also play a key role every day, but Wikipedia has generally been where LLM AIs started. But as the NY Times noted a couple of years ago, the feared impact of AI on Wikipedia was palpable in the early days of LLM AIs:
“In early 2021, a Wikipedia editor peered into the future and saw what looked like a funnel cloud on the horizon: the rise of GPT-3, a precursor to the new chatbots from OpenAI. When this editor — a prolific Wikipedian who goes by the handle Barkeep49 on the site — gave the new technology a try, he could see that it was untrustworthy. The bot would readily mix fictional elements (a false name, a false academic citation) into otherwise factual and coherent answers. But he had no doubts about its potential. “I think A.I.’s day of writing a high-quality encyclopedia is coming sooner rather than later,” he wrote in “Death of Wikipedia,” an essay that he posted under his handle on Wikipedia itself. He speculated that a computerized model could, in time, displace his beloved website and its human editors, just as Wikipedia had supplanted the Encyclopaedia Britannica, which in 2012 announced it was discontinuing its print publication.”
So it’s useful to see how Wikipedia itself has changed in this LLM AI era over the last few years. From its roots over two decade ago, as a unique internet experiment to generate ‘free’, impartial, user generated/moderated, and generally reliable content that the world can rely on in dozens of languages for over two decades now. And not be owned by billionaires as a centraized, multi-trillion dollar corporate entity like so many others.
It’s been quite a journey:
“Wikipedia marked its 22nd anniversary in January. It remains, in many ways, a throwback to the Internet’s utopian early days, when experiments with open collaboration — anyone can write and edit for Wikipedia — had yet to cede the digital terrain to multibillion-dollar corporations and data miners, advertising schemers and social-media propagandists.”

“The goal of Wikipedia, as its co-founder Jimmy Wales described it in 2004, was to create “a world in which every single person on the planet is given free access to the sum of all human knowledge.” The following year, Wales also stated, “We help the internet not suck.” Wikipedia now has versions in 334 languages and a total of more than 61 million articles. It consistently ranks among the world’s 10 most-visited websites yet is alone among that select group (whose usual leaders are Google, YouTube and Facebook) in eschewing the profit motive. Wikipedia does not run ads, except when it seeks donations, and its contributors, who make about 345 edits per minute on the site, are not paid. In seeming to repudiate capitalism’s imperatives, its success can seem surprising, even mystifying. Some Wikipedians remark that their endeavor works in practice, but not in theory.”
So it’s useful to get an update on how Wikipedia is faring in the AI maelstroms today and see what can be learned about the broader AI age tussles for content ahead.

Axios outlines it in “How AI made Wikipedia more indispensable”:
“Far from wrecking Wikipedia, the rise of AI has so far just strengthened it, Wikipedia’s outgoing leader Maryana Iskander tells Axios in an exclusive interview.”
“The big picture: Once seen as a possible casualty of the generative AI boom, and more recently a target of the MAGA right, Wikipedia has emerged as an enduring model for how to navigate the latest shifts in politics and technology.”
All this as AI Scales in many unanticipated ways going forward:

Back to Axios,
“Iskander points to the company’s values as keys to its enduring success — things like requiring sources, ensuring a neutral point of view and transparent debate.
-
“Everybody keeps predicting it’s all gonna end one day, and the opposite keeps being true,” Iskander said. “It keeps getting stronger.”
-
While other sites and services are struggling to hold on to traffic as usage of ChatGPT and other AI tools grows, Iskander says Wikipedia’s page views and usage have not yet shown signs of decline: “We’ve just become more and more relevant and more and more important.”
“Driving the news: Iskander announced last week she will leave her post as CEO of the Wikimedia Foundation, which funds and oversees Wikipedia.”
-
“Under her tenure, the organization has broadened its donor base, expanded its footprint of data centers and built a business model that seeks to keep the entirety of the site free.”
-
“I do not see us moving away from core principles like free access to knowledge for everybody,” Iskander said. “It’s about being smart about who needs to access what in what kinds of ways.”


Wikipedia has a unique ‘freemium’ model on the internet:
“While individuals, nonprofits and others can access Wikipedia without charge, the organization encourages tech companies that make massive use of its entire corpus to pay their fair share.”
-
“Rather than trying to threaten tech companies, Iskander has sought to convince them that they need to support Wikipedia if they want it as a resource, while also providing them improved access.”
-
“It has taken some creativity to make sure that the large players also are coming to the table,” she said.”
And the learnings from Wikipedia seem to be extensivel to others:
“Between the lines: Iskander also sees lessons in Wikipedia’s approach for AI companies as they seek to mitigate bias, reduce errors and ensure a healthy information ecosystem.”
-
“We’ve tried to talk about why making the models more open is the right thing to do because we do it,” Iskander said. “We’ve tried to talk about how to keep humans in the loop because we do it. We’ve tried to talk about why caring about provenance and attribution and who creates is important.”
And then there are non-commercial, political forces to contend with as well:
“Zoom in: Wikipedia faces growing attacks in the U.S. from those who don’t like the information it surface”.
“While that’s disturbing for what it signals about the direction of the country, Iskander says Wikipedia has decades of experience standing up to governments.
-
“What’s happening in the U.S. feels big because it’s the U.S.,” she said. “But Wikipedia has been dealing with these issues in an endless number of countries — India, Russia, Pakistan, Turkey — and so I think that’s made us better prepared.”
And a lot for regulators to absorb about content and synthetic content generated by AI on the internet data to come. The ‘Synthetic Data’ and ‘Synthetic Content’ I’ve written about. Out ‘Data Exhaust’ and much else turned into ever growing useful AI results, and ‘AI Slop’.

Axios expounds.
“Iskander has a suggestion for regulators weighing changes to internet law, such as amending or limiting Section 230 protections: They should employ what Wikipedia founder Jimmy Wales has called the “Wikipedia Test” to make sure proposed changes actually protect the flow of information in the public interest.”
-
“That means asking whether a particular law or rule is good or bad for Wikipedia. Iskander says that’s “just a way of thinking through what are the consequences and the impacts” on many similar outfits.”
-
“Well-meaning but poorly thought-out changes, she said, could threaten open-source and crowdsourced information sources.”
-
“Whatever we change, we’ve got to keep making space for different kinds of models,” she said.”
It’s all a useful summary on where we are with AI and Data in these early days of AI Tech Wave.

The only thing certain is that Jervon’s paradox is going to mean we are going to need a far bigger pool of Data than we think. AI icon Ilya Sutskever’s ‘peak data’ warnings notwithstanding.
And the battles and tussles over content copyrights for AI data ‘fair use’ in AI training and inference will continue. This week alone saw some drama at the US Copyright office and the Trump administration that is of note.
But the broader issue is that data quests to continue to feed AIs both for the digital and physical worlds is just beginning. And Wikipedia is one of the canaries in that data coalmine. Stay tuned.
(NOTE: The discussions here are for information purposes only, and not meant as investment advice at any time. Thanks for joining us here)


