
AI: Scaling AI Evaluations ('Evals'). RTZ #582

As we see the relentless competition amongst the LLM AI companies to outdo each other on Scaling AI on both the software and hardware fronts, it’s easy to overlook the underlying accelerating challenges of assessing the relative improvements of these models in the first place. And these models are increasingly being used with each other for an ever changing array of AI Applications and Services in Box 6 of the AI Tech Stack below.
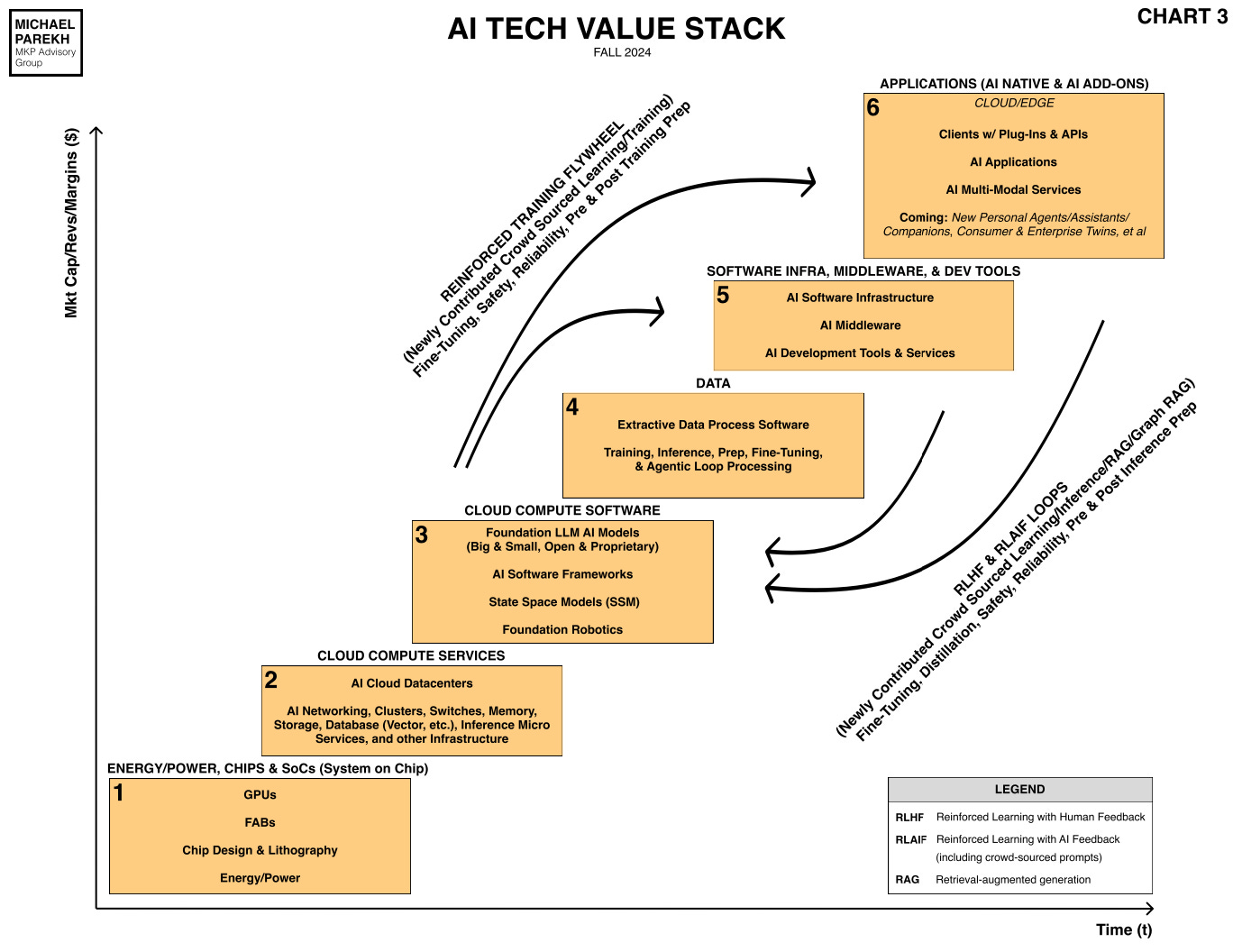
So then there is also the urgent need to measure how well these models work WITH each other. In other words, their ‘interoperability’. I’d like to discuss these issues today.
First there is the issue of evaluating these accelerating LLM AI and related AI reasoning and agentic capabilities as they all race towards AGI, however defined. Then there is the issue of figuring out how to evaluate these models as they interoperate with each other. Let’s look at each piece separately.
Let’s begin with LLM AI ‘Evaluations’, a topic I’ve discussed before. These are in addition to discerning how the LLM AIs work in the first place, along with their ‘explainability’, ‘interpretability’ (transparency), and other issues I’ve discussed in earlier posts.

As Time magazine outlines in “AI Models Are Getting Smarter. New Tests Are Racing to Catch Up”:
“Despite their expertise, AI developers don’t always know what their most advanced systems are capable of—at least, not at first. To find out, systems are subjected to a range of tests—often called evaluations, or ‘evals’—designed to tease out their limits. But due to rapid progress in the field, today’s systems regularly achieve top scores on many popular tests, including SATs and the U.S. bar exam, making it harder to judge just how quickly they are improving.”
“‘A new set of much more challenging evals has emerged in response, created by companies, nonprofits, and governments. Yet even on the most advanced evals, AI systems are making astonishing progress. In November, the nonprofit research institute Epoch AI announced a set of exceptionally challenging math questions developed in collaboration with leading mathematicians, called FrontierMath, on which currently available models scored only 2%. Just one month later, OpenAI’s newly-announced o3 model achieved a score of 25.2%, which Epoch’s director, Jaime Sevilla, describes as “far better than our team expected so soon after release.”

“Amid this rapid progress, these new evals could help the world understand just what advanced AI systems can do, and—with many experts worried that future systems may pose serious risks in domains like cybersecurity and bioterrorism—serve as early warning signs, should such threatening capabilities emerge in future.”
None of this is easy as it looks from the outside:
“In the early days of AI, capabilities were measured by evaluating a system’s performance on specific tasks, like classifying images or playing games, with the time between a benchmark’s introduction and an AI matching or exceeding human performance typically measured in years. It took five years, for example, before AI systems surpassed humans on the ImageNet Large Scale Visual Recognition Challenge, established by Professor Fei-Fei Li and her team in 2010. And it was only in 2017 that an AI system (Google DeepMind’s AlphaGo) was able to beat the world’s number one ranked player in Go, an ancient, abstract Chinese boardgame—almost 50 years after the first program attempting the task was written.”
There are now intricate processes set up to do these evaluation tasks.
“Evals take many forms, and their complexity has grown alongside model capabilities. Virtually all major AI labs now “red-team” their models before release, systematically testing their ability to produce harmful outputs, bypass safety measures, or otherwise engage in undesirable behavior, such as deception. Last year, companies including OpenAI, Anthropic, Meta, and Google made voluntary commitments to the Biden administration to subject their models to both internal and external red-teaming “in areas including misuse, societal risks, and national security concerns.”
“Other tests assess specific capabilities, such as coding, or evaluate models’ capacity and propensity for potentially dangerous behaviors like persuasion, deception, and large-scale biological attacks.”
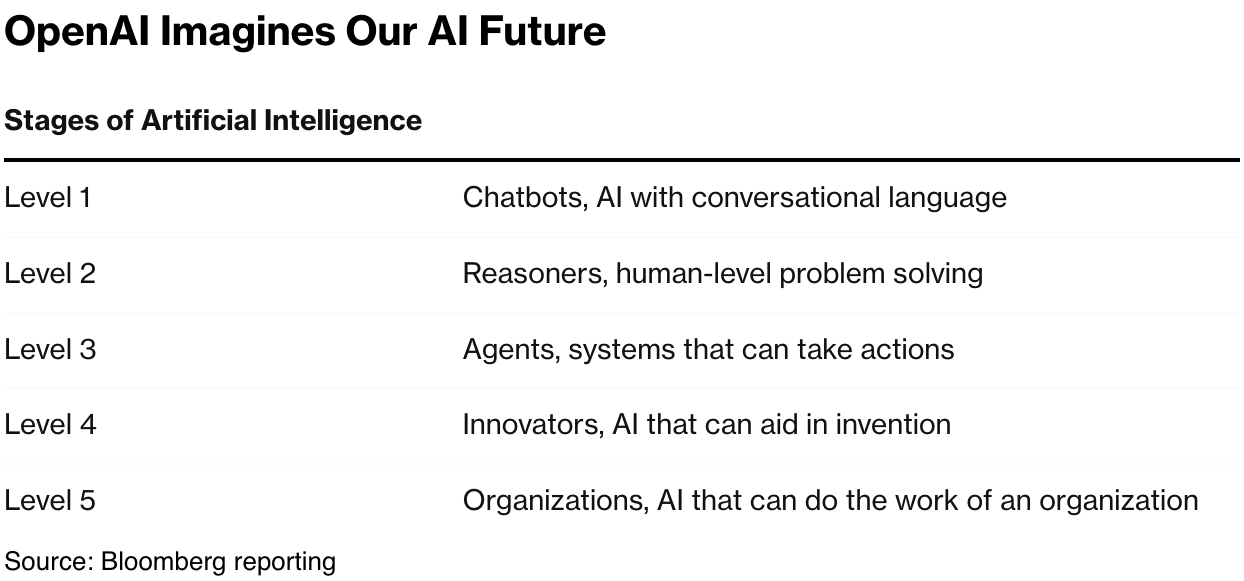
It’s useful to understand the key benchmark tests and evaluations, especially as they move up the levels to AGI:
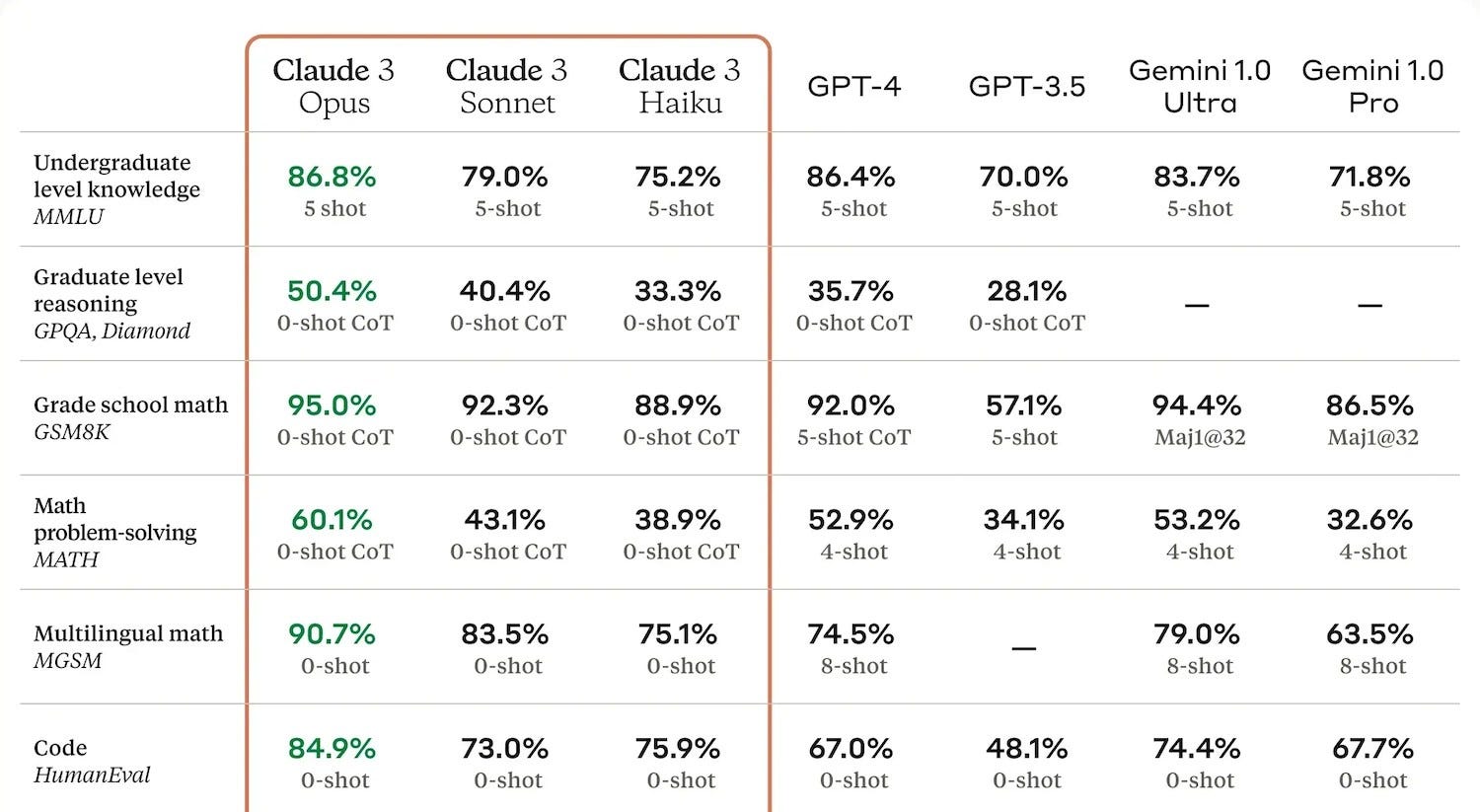
“Perhaps the most popular contemporary benchmark is Measuring Massive Multitask Language Understanding (MMLU), which consists of about 16,000 multiple-choice questions that span academic domains like philosophy, medicine, and law. OpenAI’s GPT-4o, released in May, achieved 88%, while the company’s latest model, o1, scored 92.3%. Because these large test sets sometimes contain problems with incorrectly-labelled answers, attaining 100% is often not possible, explains Marius Hobbhahn, director and co-founder of Apollo Research, an AI safety nonprofit focused on reducing dangerous capabilities in advanced AI systems. Past a point, “more capable models will not give you significantly higher scores,” he says.”
The challenge of setting these tests up, along with mechanisms to address the inevitable ‘gaming’ of these systems, is an ongoing issue.
“Designing evals to measure the capabilities of advanced AI systems is “astonishingly hard,” Hobbhahn says—particularly since the goal is to elicit and measure the system’s actual underlying abilities, for which tasks like multiple-choice questions are only a proxy. “You want to design it in a way that is scientifically rigorous, but that often trades off against realism, because the real world is often not like the lab setting,” he says. Another challenge is data contamination, which can occur when the answers to an eval are contained in the AI’s training data, allowing it to reproduce answers based on patterns in its training data rather than by reasoning from first principles.”
“Another issue is that evals can be “gamed” when “either the person that has the AI model has an incentive to train on the eval, or the model itself decides to target what is measured by the eval, rather than what is intended,” says Hobbahn.”

There are of course national security aspects to these tasks.
“These results don’t mean that current AI systems can automate AI research and development. “Eventually, this is going to have to be superseded by a harder eval,” says Wijk. But given that the possible automation of AI research is increasingly viewed as a national security concern—for example, in the National Security Memorandum on AI, issued by President Biden in October—future models that excel on this benchmark may be able to improve upon themselves, exacerbating human researchers’ lack of control over them.”
And while the models are getting more capable at these specialized tasks, there is so much that remains to be done to match basic human capabilities.
“Even as AI systems ace many existing tests, they continue to struggle with tasks that would be simple for humans. “They can solve complex closed problems if you serve them the problem description neatly on a platter in the prompt, but they struggle to coherently string together long, autonomous, problem-solving sequences in a way that a person would find very easy,” Andrej Karpathy, an OpenAI co-founder who is no longer with the company, wrote in a post on X in response to FrontierMath’s release.”
The latest models like OpenAI’s o3 are going up against tests like ARC-AGI:
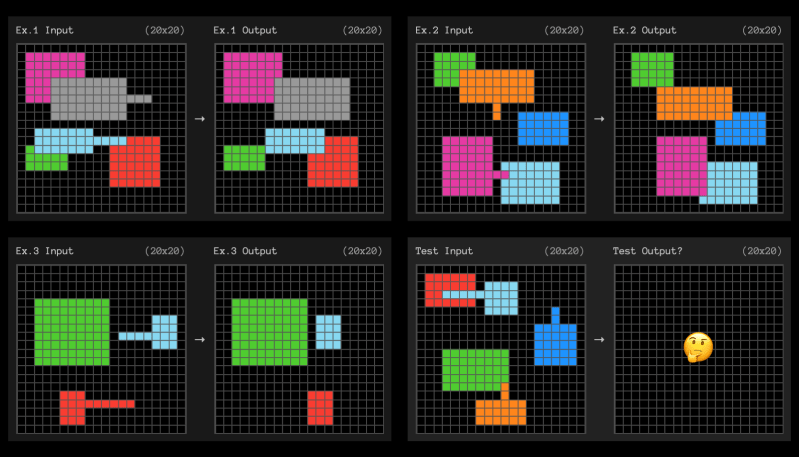
“One eval seeking to move beyond just testing for knowledge recall is ARC-AGI, created by prominent AI researcher François Chollet to test an AI’s ability to solve novel reasoning puzzles. For instance, a puzzle might show several examples of input and output grids, where shapes move or change color according to some hidden rule. The AI is then presented with a new input grid and must determine what the corresponding output should look like, figuring out the underlying rule from scratch. Although these puzzles are intended to be relatively simple for most humans, AI systems have historically struggled with them. However, recent breakthroughs suggest this is changing: OpenAI’s o3 model has achieved significantly higher scores than prior models, which Chollet says represents “a genuine breakthrough in adaptability and generalization.”
The Urgent need for far better ‘Evals’ is upon us:
“New evals, simple and complex, structured and “vibes”-based, are being released every day. AI policy increasingly relies on evals, both as they are being made requirements of laws like the European Union’s AI Act, which is still in the process of being implemented, and because major AI labs like OpenAI, Anthropic, and Google DeepMind have all made voluntary commitments to halt the release of their models, or take actions to mitigate possible harm, based on whether evaluations identify any particularly concerning harms.”
And these testing imperatives are of course safety issues here and abroad.
“On the basis of voluntary commitments, The U.S. and U.K. AI Safety Institutes have begun evaluating cutting-edge models before they are deployed. In October, they jointly released their findings in relation to the upgraded version of Anthropic’s Claude 3.5 Sonnet model, paying particular attention to its capabilities in biology, cybersecurity, and software and AI development, as well as to the efficacy of its built-in safeguards. They found that “in most cases the built-in version of the safeguards that US AISI tested were circumvented, meaning the model provided answers that should have been prevented.” They note that this is “consistent with prior research on the vulnerability of other AI systems.” In December, both institutes released similar findings for OpenAI’s o1 model.”
The question of who creates and maintains these tests is another issue.
“While some for-profit companies, such as Scale AI, do conduct independent evals for their clients, most public evals are created by nonprofits and governments, which Hobbhahn sees as a result of “historical path dependency.”
“I don’t think it’s a good world where the philanthropists effectively subsidize billion dollar companies,” he says. “I think the right world is where eventually all of this is covered by the labs themselves. They’re the ones creating the risk.”.
Also of importance is the costs of these testing processes.
“AI evals are “not cheap,” notes Epoch’s Besiroglu, who says that costs can quickly stack up to the order of between $1,000 and $10,000 per model, particularly if you run the eval for longer periods of time, or if you run it multiple times to create greater certainty in the result. While labs sometimes subsidize third-party evals by covering the costs of their operation, Hobbhahn notes that this does not cover the far-greater costs of actually developing the evaluations. Still, he expects third-party evals to become a norm going forward, as labs will be able to point to them to evidence due-diligence in safety-testing their models, reducing their liability.”
And it’s an accelerating race.
“As AI models rapidly advance, evaluations are racing to keep up. Sophisticated new benchmarks—assessing things like advanced mathematical reasoning, novel problem-solving, and the automation of AI research—are making progress, but designing effective evals remains challenging, expensive, and, relative to their importance as early-warning detectors for dangerous capabilities, underfunded. With leading labs rolling out increasingly capable models every few months, the need for new tests to assess frontier capabilities is greater than ever. By the time an eval saturates, “we need to have harder evals in place, to feel like we can assess the risk,” says Wijk.”
The whole piece is worth reading for the complexity and the accelerating ‘whack-a-mole’ nature of this race as LLM AIs scale and improve exponentially.
Next, the issue of how these LLM AI models interoperate with each other, and how THAT can be also evaluated.
As the Decoder outlines in “Anthropic’s Claude AI cooperates better than OpenAI and Google models, study finds”:

“A new research paper reveals significant differences in how AI language models work together, with Anthropic’s Claude 3.5 Sonnet showing superior cooperation skills compared to competitors.”
“The research team tested different AI models using a classic “donor game” in which AI agents could share and benefit from resources over multiple generations.”
“Anthropic’s Claude 3.5 Sonnet emerged as the clear winner, consistently developing stable cooperation patterns that led to higher overall resource gains. Google’s Gemini 1.5 Flash and OpenAI’s GPT-4o didn’t fare as well in the tests. In fact, GPT-4o-based agents became increasingly uncooperative over time, while Gemini agents showed minimal cooperation.”
Some unexpected behaviors emerged in the different models.
“When researchers added the ability for agents to penalize uncooperative behavior, the differences became even more pronounced. Claude 3.5’s performance improved further, with its agents developing increasingly complex strategies over generations, including specific mechanisms to reward teamwork and punish those who tried to take advantage of the system without contributing. In contrast, Gemini’s cooperation levels declined significantly when punishment options were introduced.”
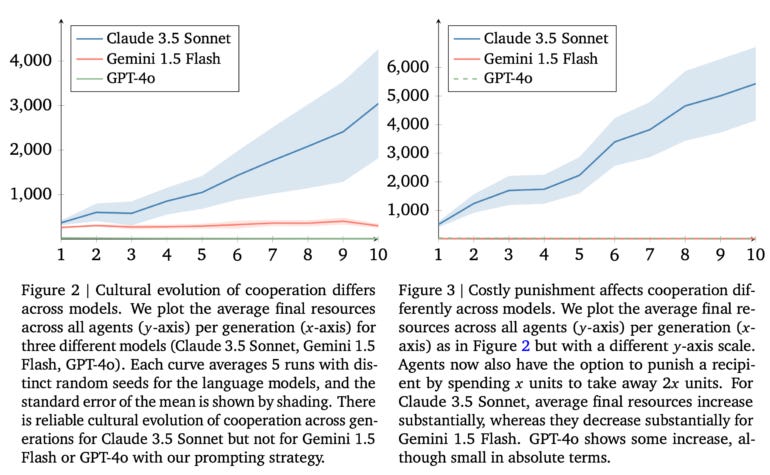
“Looking toward real-world applications, the findings could have important implications as AI systems increasingly need to work together in practical applications. However, the researchers acknowledge several limitations in their study. They only tested groups using the same AI model rather than mixing different ones, and the simple game setup doesn’t reflect the complexity of real-world scenarios.”
And there remains work to be done on the newer AI innovations:
“The study also didn’t include newer models like OpenAI’s o1 or Google’s recently released Gemini 2.0, which could be essential for future AI agent applications.”
And thinking through new questions themselves:
“The researchers emphasize that AI cooperation isn’t always desirable – for instance, when it comes to potential price fixing. They say the key challenge moving forward will be developing AI systems that cooperate in ways that benefit humans while avoiding potentially harmful collusion.”

All this points to the hard task ahead not just in building ever Scaling Trustworthy AI models that excel at AI reasoning, agenting and more, but also the need for Scaling their Evaluations. Both their performances relative to ever-changing external benchmarks, and evaluating their ‘interoperability’.
A lot of AI work to be done in this AI Tech Wave in 2025 and beyond. Stay tuned.
(NOTE: The discussions here are for information purposes only, and not meant as investment advice at any time. Thanks for joining us here)



